Ch. 7: Data exploration
Key questions:
- 7.3.4. #1
- 7.5.1.1 #2
- 7.5.3.1. #2, 4
cut_width: specify binsize of each cut (often use withgeom_boxplot)cut_number: specify number of groups to make, allowing for variable binsize (often use withgeom_boxplot)geom_histogram: key args arebins,binwidthgeom_freqpoly: for if you want to have overlapping histograms (so outputs lines instead)- can set y as
..density..to equalize scale of each (similar to howgeom_densitydoes).
- can set y as
geom_boxplot: adjust outliers withoutlier.colour,outlier.fill, …geom_violin: Creates double sided histograms for each factor of xgeom_bin2d: scatter plot of x and y values, but use shading to determine count/density in each pointgeom_hex: same asgeom_bin2dbut hexagon instead of square shapes are shaded inreorder: arg1 = variable to reorder, arg2 = variable to reorder it by arg3 = function to reorder by (e.g. median, mean, max…)coord_cartesian: adjust x,y window w/o filtering out values that are excluded from viewxlim;ylim: adjust window and filter out values not within window (same method asscale_x(/y)_continuous)- these v.
coord_cartesianis important for geoms likegeom_smooththat aggregate as they visualize
- these v.
ifelse: vectorized if else (not to be confused withifandelsefunctions)dplyr::if_elseis more strict alternative
case_when: create new variable that relies on complex combination of existing variables- often use when you have complex or multiple
ifelsestatements accruing
- often use when you have complex or multiple
7.3: Variation
7.3.4.
1. Explore the distribution of each of the x, y, and z variables in diamonds. What do you learn? Think about a diamond and how you might decide which dimension is the length, width, and depth.
x has some 0s which signifies a data colletion error, y and z have extreme outliers (z more so).
x_hist <- ggplot(diamonds)+
geom_histogram(aes(x = x), binwidth = 0.1)+
coord_cartesian(xlim = c(0, 10))
y_hist <- ggplot(diamonds)+
geom_histogram(aes(x = y), binwidth = 0.1)+
coord_cartesian(xlim = c(0, 10))
z_hist <- ggplot(diamonds)+
geom_histogram(aes(x = z), binwidth = 0.1)+
coord_cartesian(xlim = c(0, 10))
gridExtra::grid.arrange(x_hist, y_hist, z_hist, ncol = 1)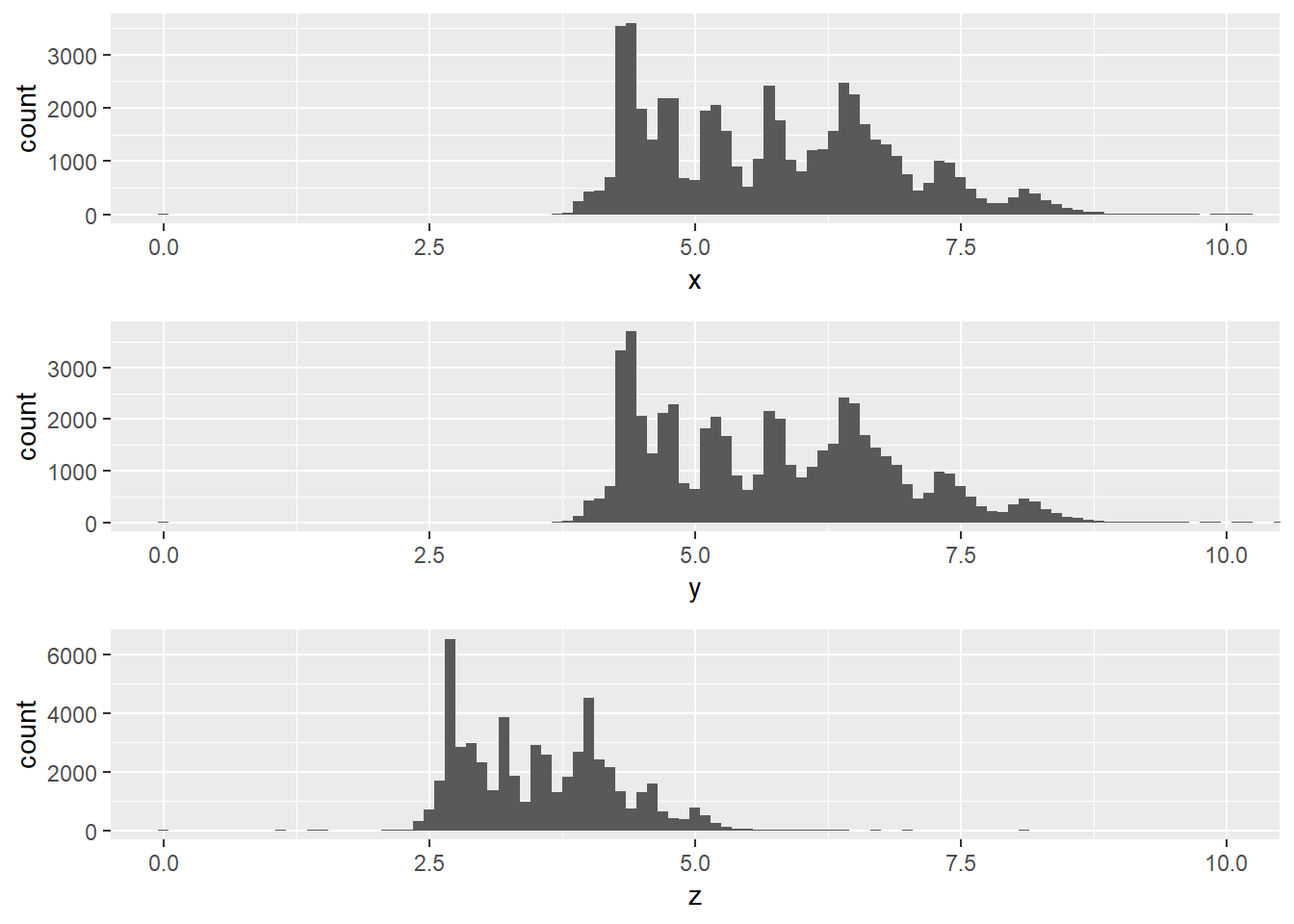
- All three have peaks and troughs on even points. X and y have more similar distributions than z.
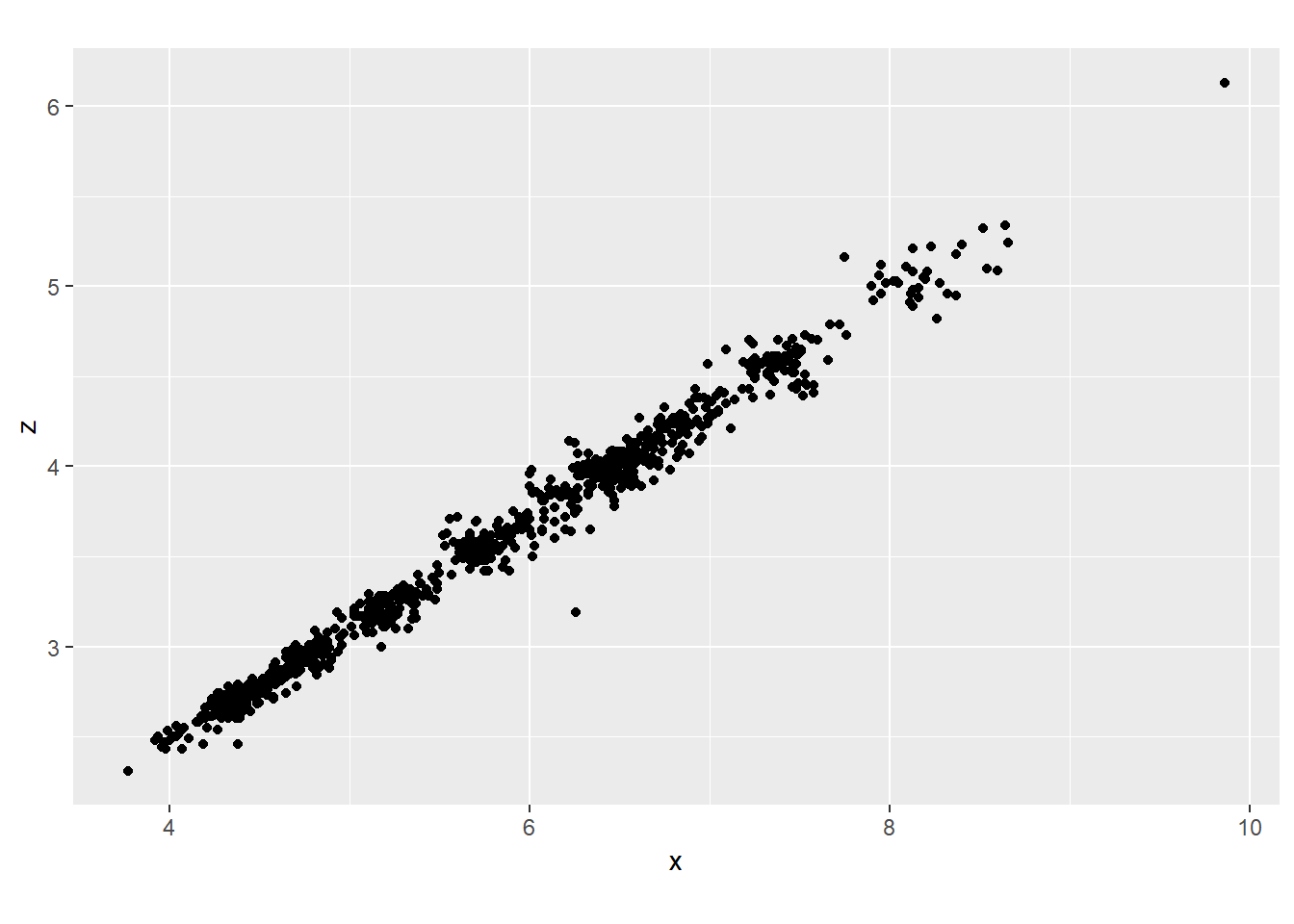
I would say that x and y are likely length and width and z depth because diamonds are typically circular on the face so will have the same ratio of length and width and we see this is the case for the x and y dimensions, whereas z tends to be more shallow.
diamonds %>%
sample_n(1000) %>%
ggplot()+
geom_point(aes(x, y))+
coord_fixed()
diamonds %>%
sample_n(1000) %>%
ggplot()+
geom_point(aes(x, z))+
coord_fixed()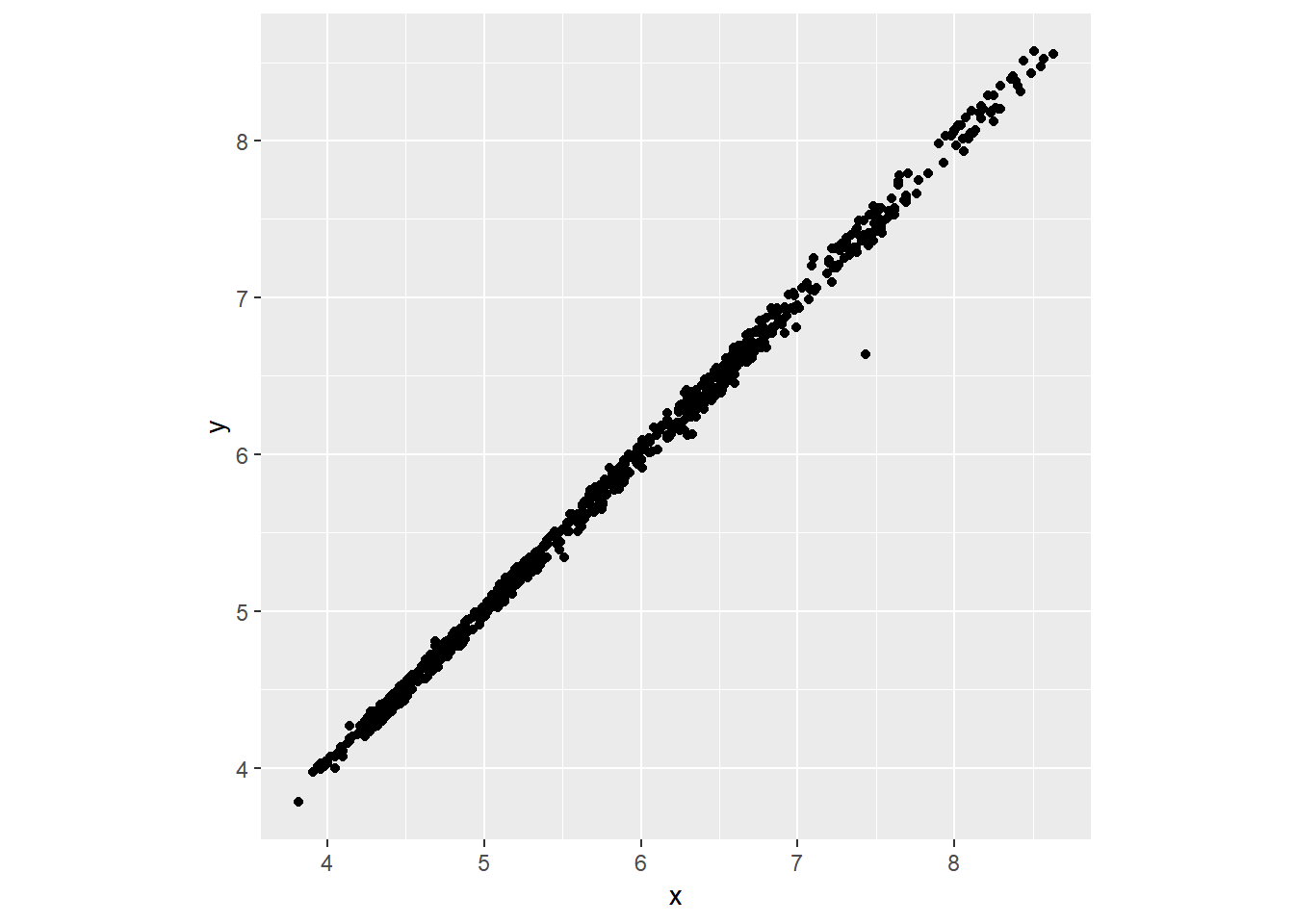
2. Explore the distribution of price. Do you discover anything unusual or surprising? (Hint: Carefully think about the binwidth and make sure you try a wide range of values.)
ggplot(diamonds)+
geom_histogram(aes(x = price), binwidth=10)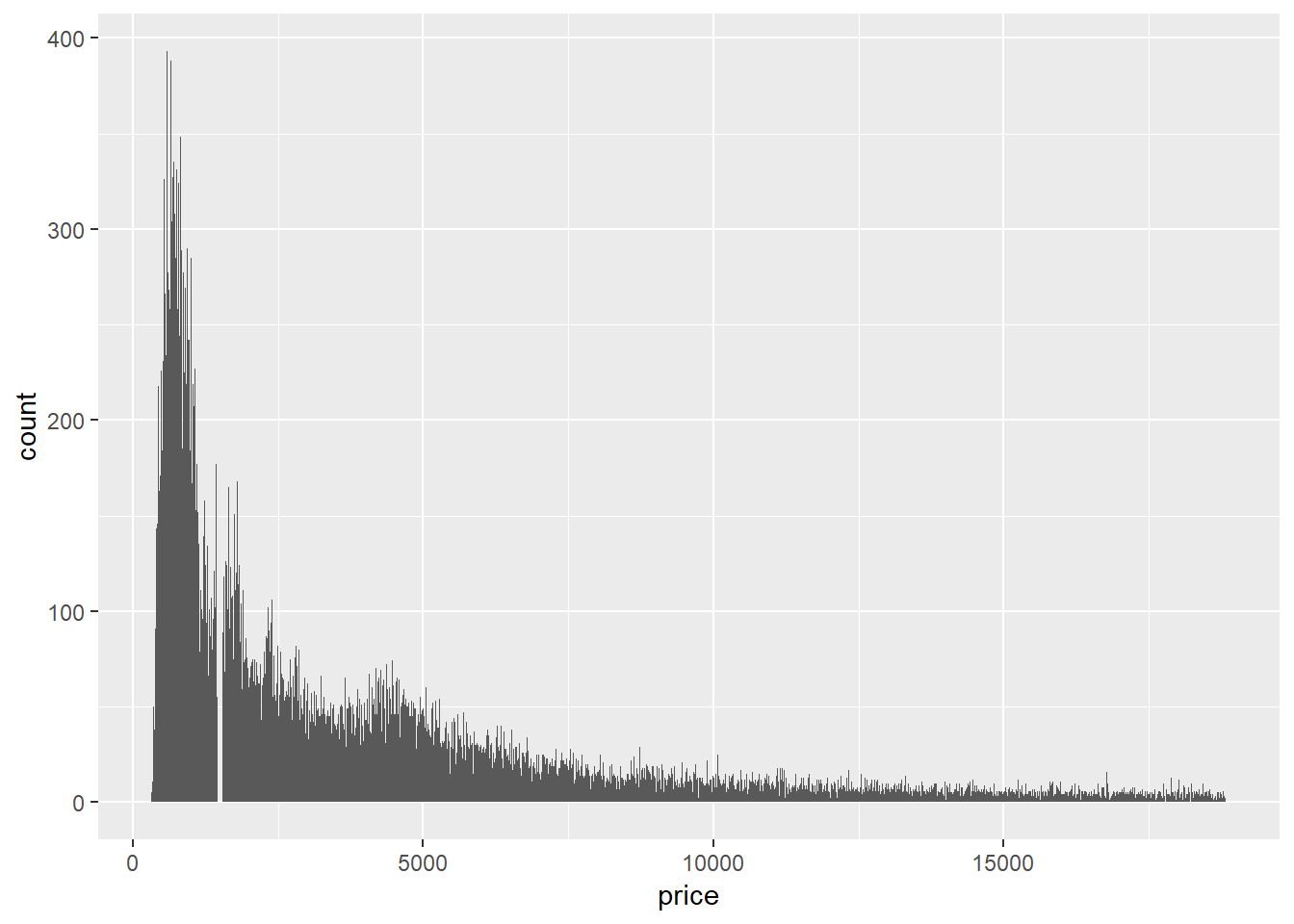
Price is right skewed.
Also notice that from ~1450 to ~1550 there are diamonds.
ggplot(diamonds)+
geom_histogram(aes(x = price), binwidth = 5)+coord_cartesian(xlim = c(1400,1600))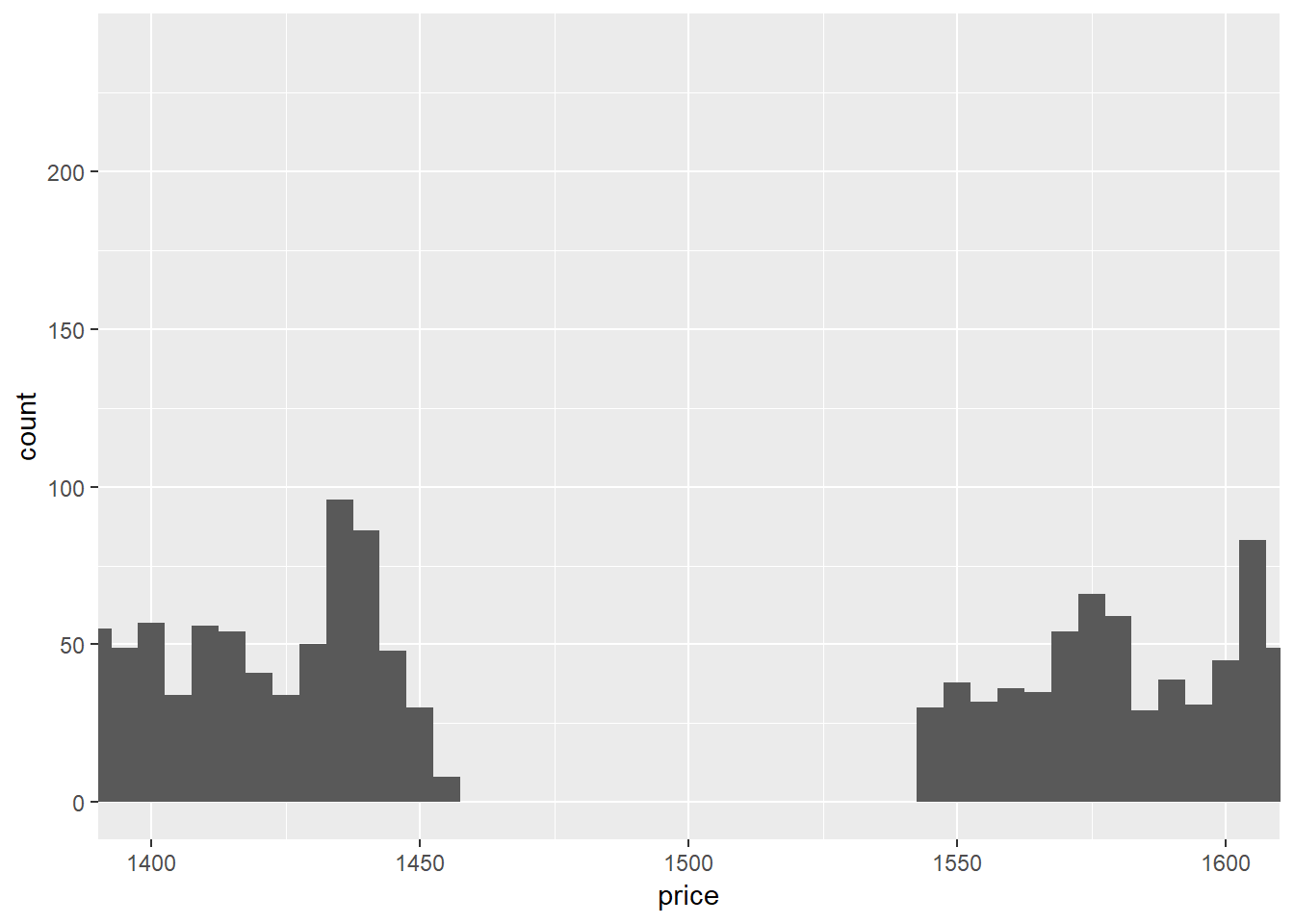
3. How many diamonds are 0.99 carat? How many are 1 carat? What do you think is the cause of the difference?
filter(diamonds, carat == 0.99) %>%
count()## # A tibble: 1 x 1
## n
## <int>
## 1 23filter(diamonds, carat == 1) %>%
count()## # A tibble: 1 x 1
## n
## <int>
## 1 1558For visual scale.
ggplot(diamonds)+
geom_histogram(aes(x=carat), binwidth=.01)+
coord_cartesian(xlim=c(.99,1))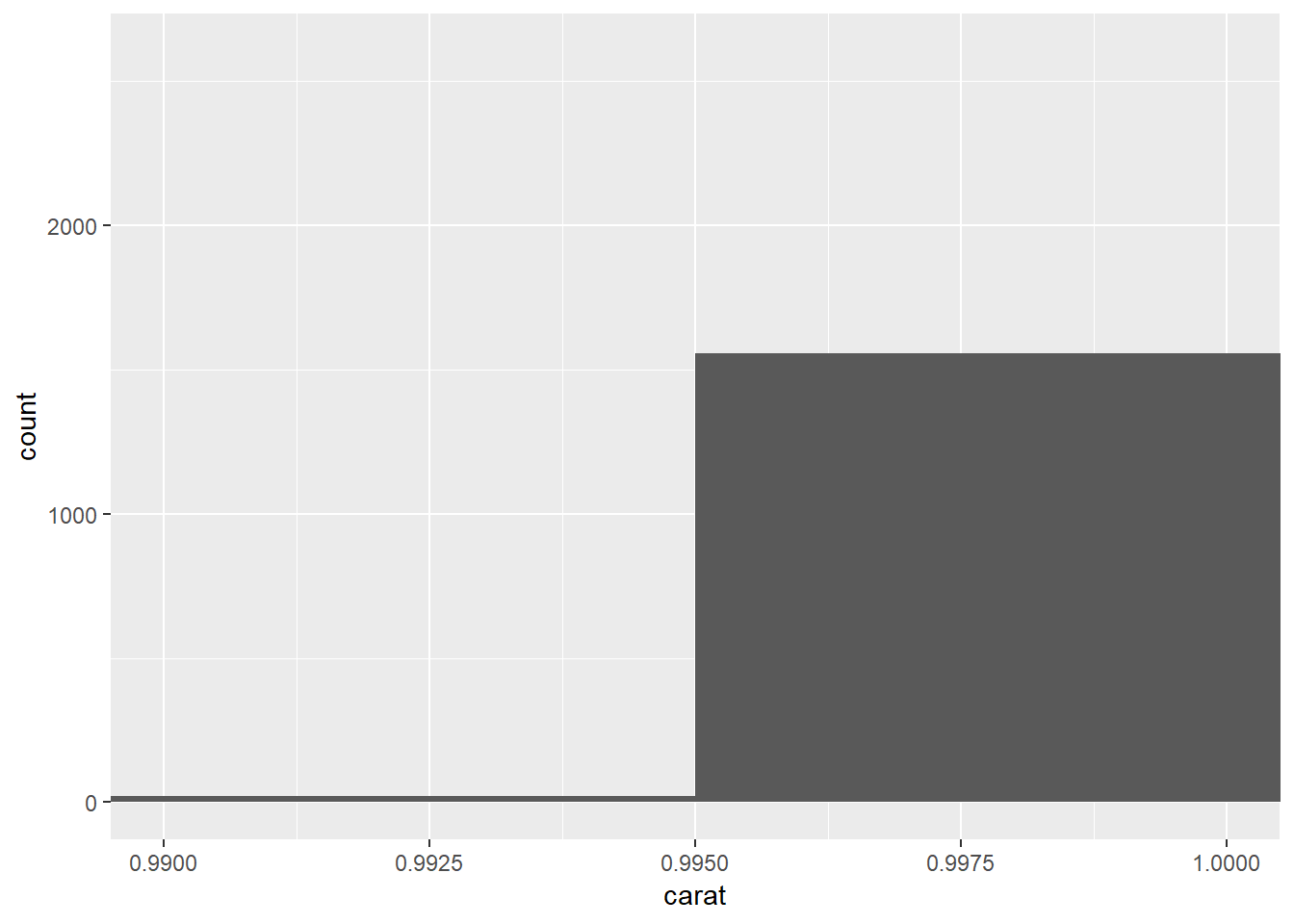
The difference may be caused by jewlers rounding-up because people want to buy ‘1’ carat diamonds not 0.99 carat diamonds. It could also be that some listings are simpoly only in integers19.
4.Compare and contrast coord_cartesian() vs xlim() or ylim() when zooming in on a histogram. What happens if you leave binwidth unset? What happens if you try and zoom so only half a bar shows?
coord_cartesian does not change data ust window view where as xlim and ylim will get rid of data outside of domain20.
7.4: Missing values
7.4.1.
1. What happens to missing values in a histogram? What happens to missing values in a bar chart? Why is there a difference?
With numeric data they both filter out NAs, though for categorical / character variables the barplot will create a seperate olumn with the category. This is because NA can just be thought of as another category though it is difficulty to place it within a distribution of values.
Treats these the same.
mutate(diamonds, carattest=ifelse(carat<1.5 & carat>.7, NA, carat)) %>%
ggplot() +
geom_histogram(aes(x=carattest))## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.## Warning: Removed 20543 rows containing non-finite values (stat_bin).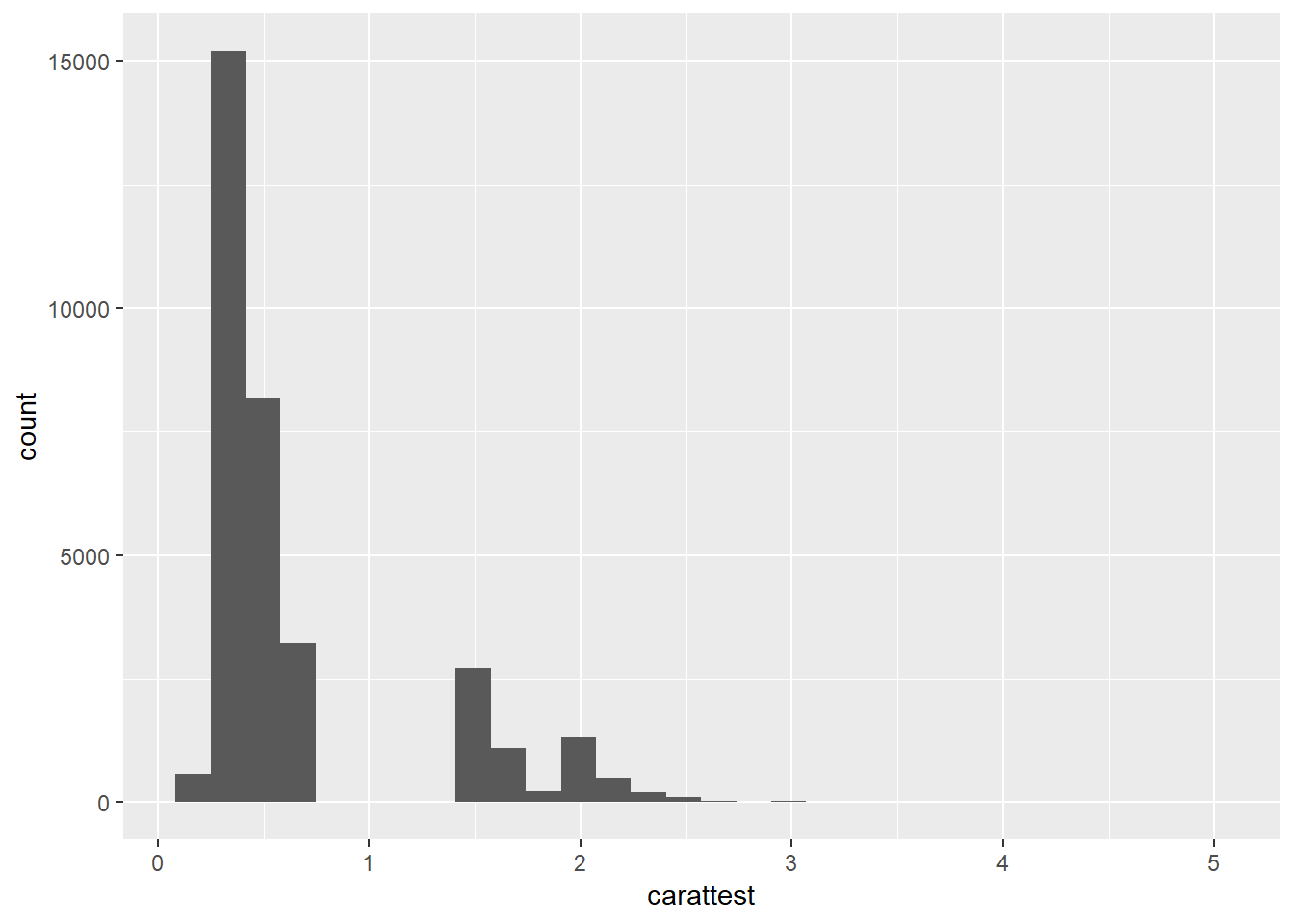
mutate(diamonds, carattest=ifelse(carat<1.5 & carat>.7, NA, color)) %>%
ggplot() +
geom_bar(aes(x=carattest))## Warning: Removed 20543 rows containing non-finite values (stat_count).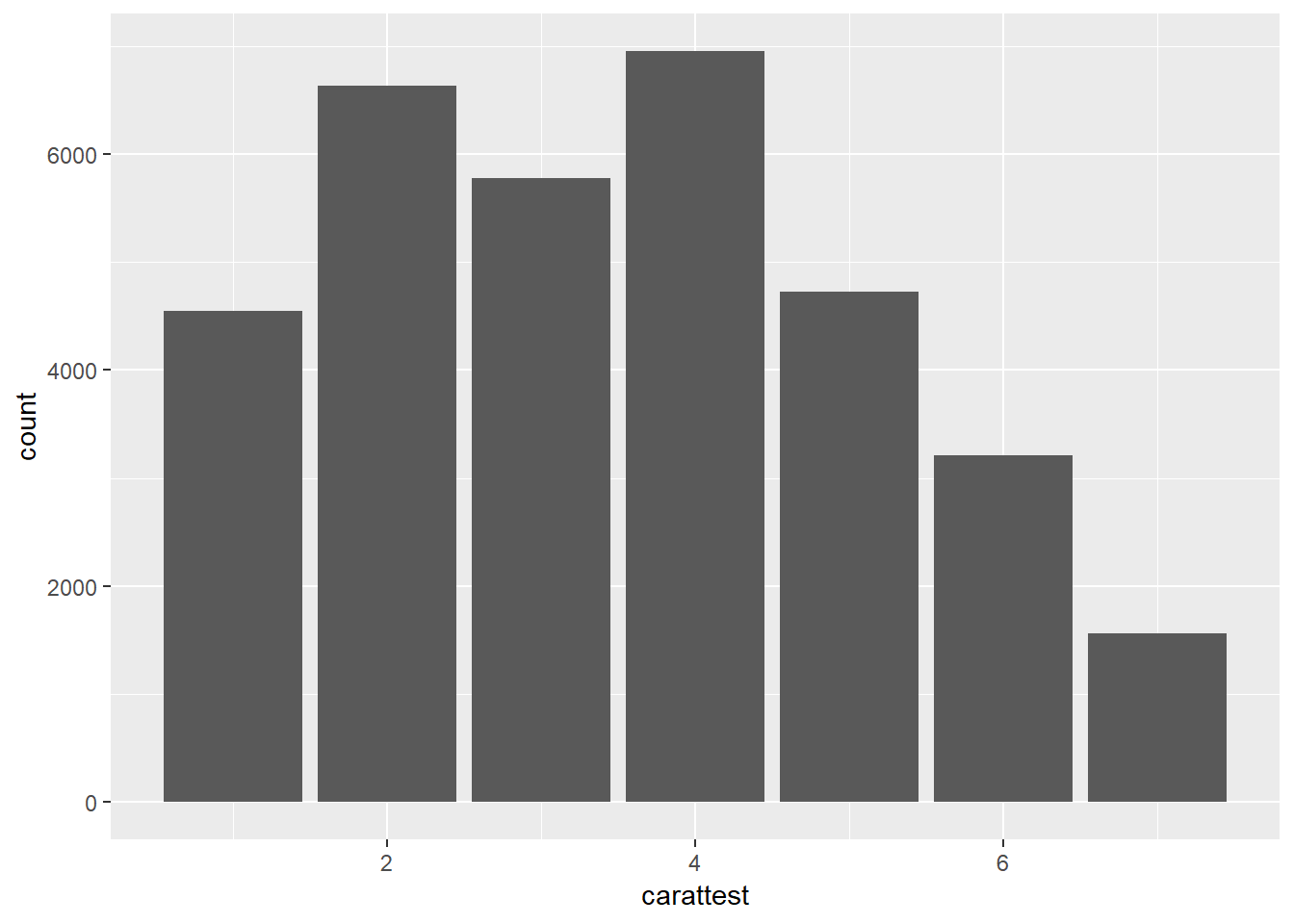
For character than it creates a new bar for NAs
mutate(diamonds, carattest=ifelse(carat<1.5 & carat>.7, NA, color)) %>%
ggplot() +
geom_bar(aes(x = as.character(carattest)))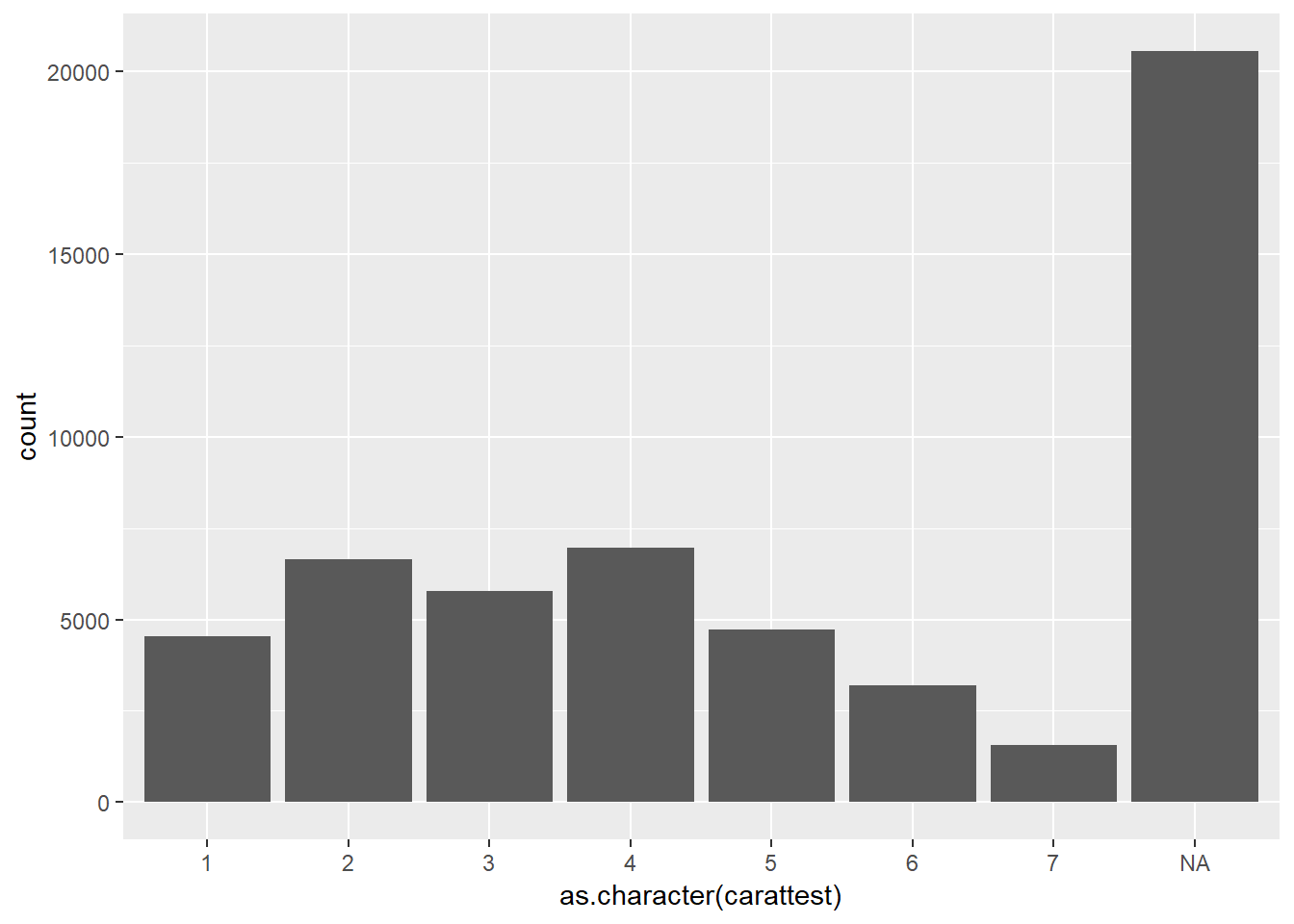
2. What does na.rm = TRUE do in mean() and sum()?
Filters it out of the vector of values.
7.5: Covariation
7.5.1.1.
1. Use what you’ve learned to improve the visualisation of the departure times of cancelled vs. non-cancelled flights.
Looks like while non-cancelled flights happen at similar frequency in mornings and evenings, cancelled flights happen at a greater frequency in the evenings.
nycflights13::flights %>%
mutate(
cancelled = is.na(dep_time),
sched_hour = sched_dep_time %/% 100,
sched_min = sched_dep_time %% 100,
sched_dep_time = sched_hour + sched_min / 60
) %>%
ggplot(mapping = aes(x=sched_dep_time, y=..density..)) +
geom_freqpoly(mapping = aes(colour = cancelled), binwidth = .25)+
xlim(c(5,25))## Warning: Removed 1 rows containing non-finite values (stat_bin).## Warning: Removed 4 rows containing missing values (geom_path).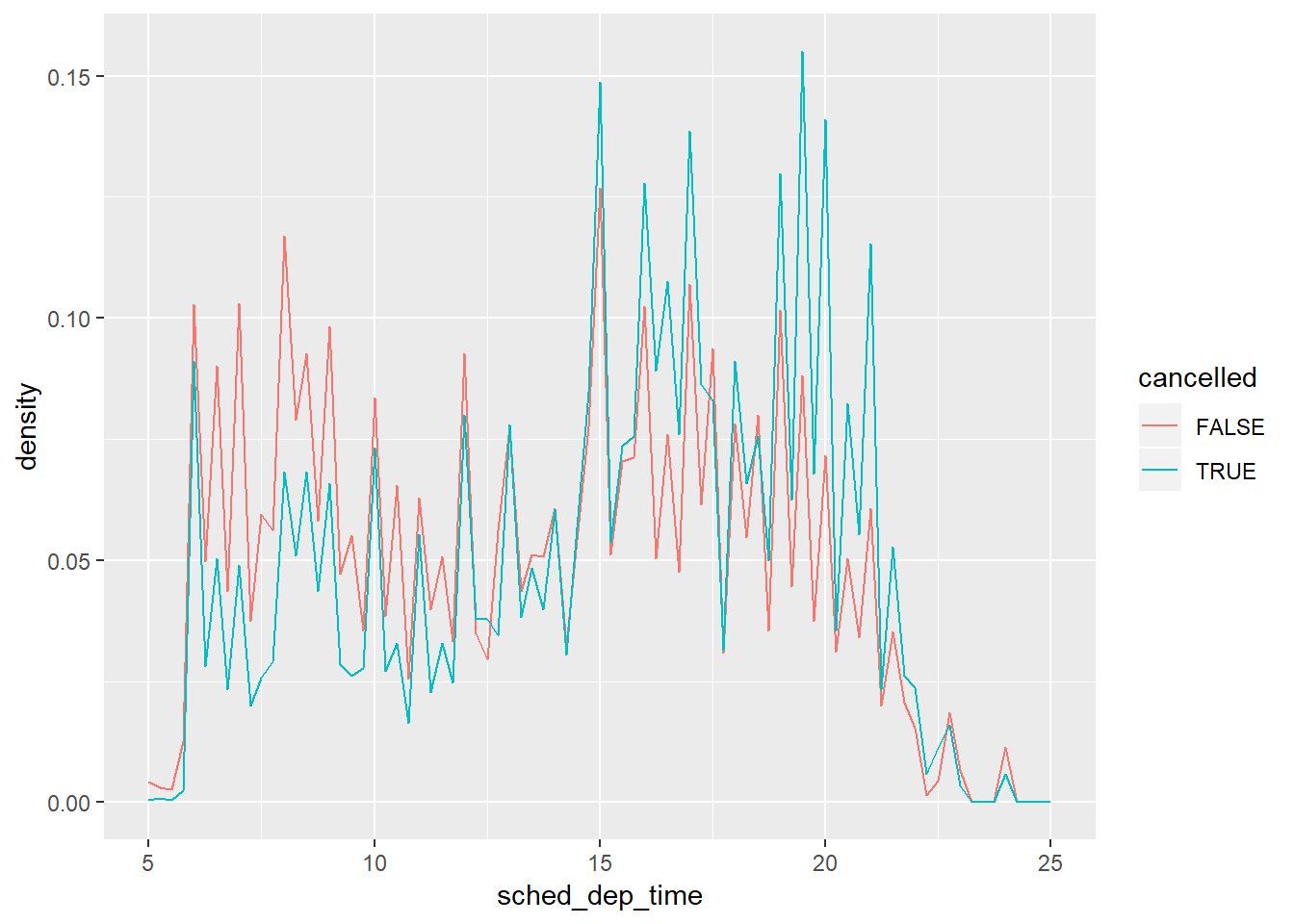
Let’s look at the same plot but smooth the distributions to make the pattern easier to see.
nycflights13::flights %>%
mutate(
cancelled = is.na(dep_time),
sched_hour = sched_dep_time %/% 100,
sched_min = sched_dep_time %% 100,
sched_dep_time = sched_hour + sched_min / 60
) %>%
ggplot(mapping = aes(x=sched_dep_time)) +
geom_density(mapping = aes(fill = cancelled), alpha = 0.30)+
xlim(c(5,25))## Warning: Removed 1 rows containing non-finite values (stat_density).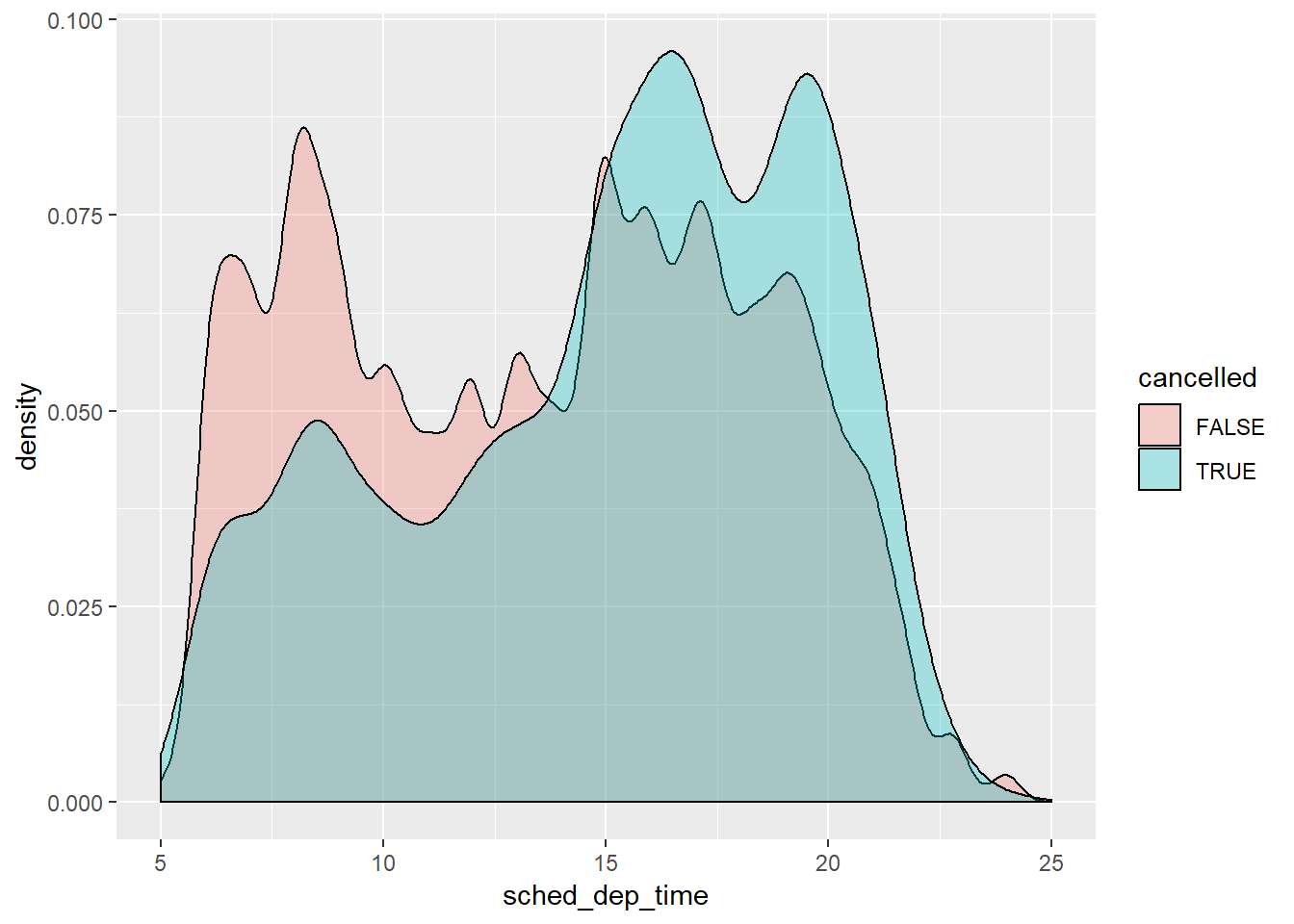
2.What variable in the diamonds dataset is most important for predicting the price of a diamond? How is that variable correlated with cut? Why does the combination of those two relationships lead to lower quality diamonds being more expensive?
carat is the most important for predicting price.
cor(diamonds$price, select(diamonds, carat, depth, table, x, y, z))## carat depth table x y z
## [1,] 0.9215913 -0.0106474 0.1271339 0.8844352 0.8654209 0.8612494fair cut seem to associate with a higher carat thus while lower quality diamonds may be selling for more that is being driven by the carat of the diamond (the most important factor in price) and the quality simply cannot offset this.
ggplot(data = diamonds, aes(x = cut, y = carat))+
geom_boxplot()+
coord_flip()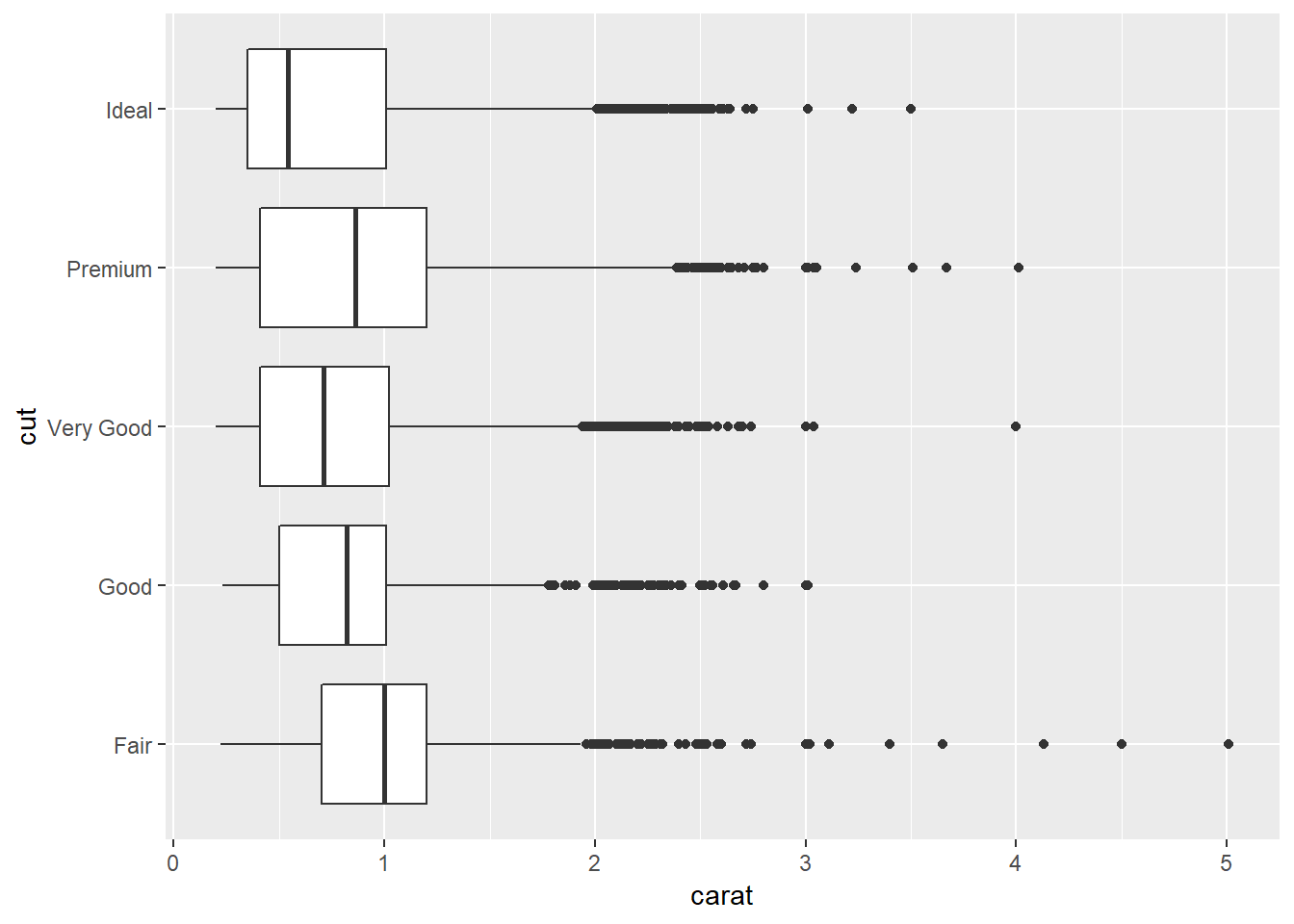
3.Install the ggstance package, and create a horizontal boxplot. How does this compare to using coord_flip()?
ggplot(diamonds)+
ggstance::geom_boxploth(aes(x = carat, y = cut))
ggplot(diamonds)+
geom_boxplot(aes(x = cut, y = carat))+
coord_flip()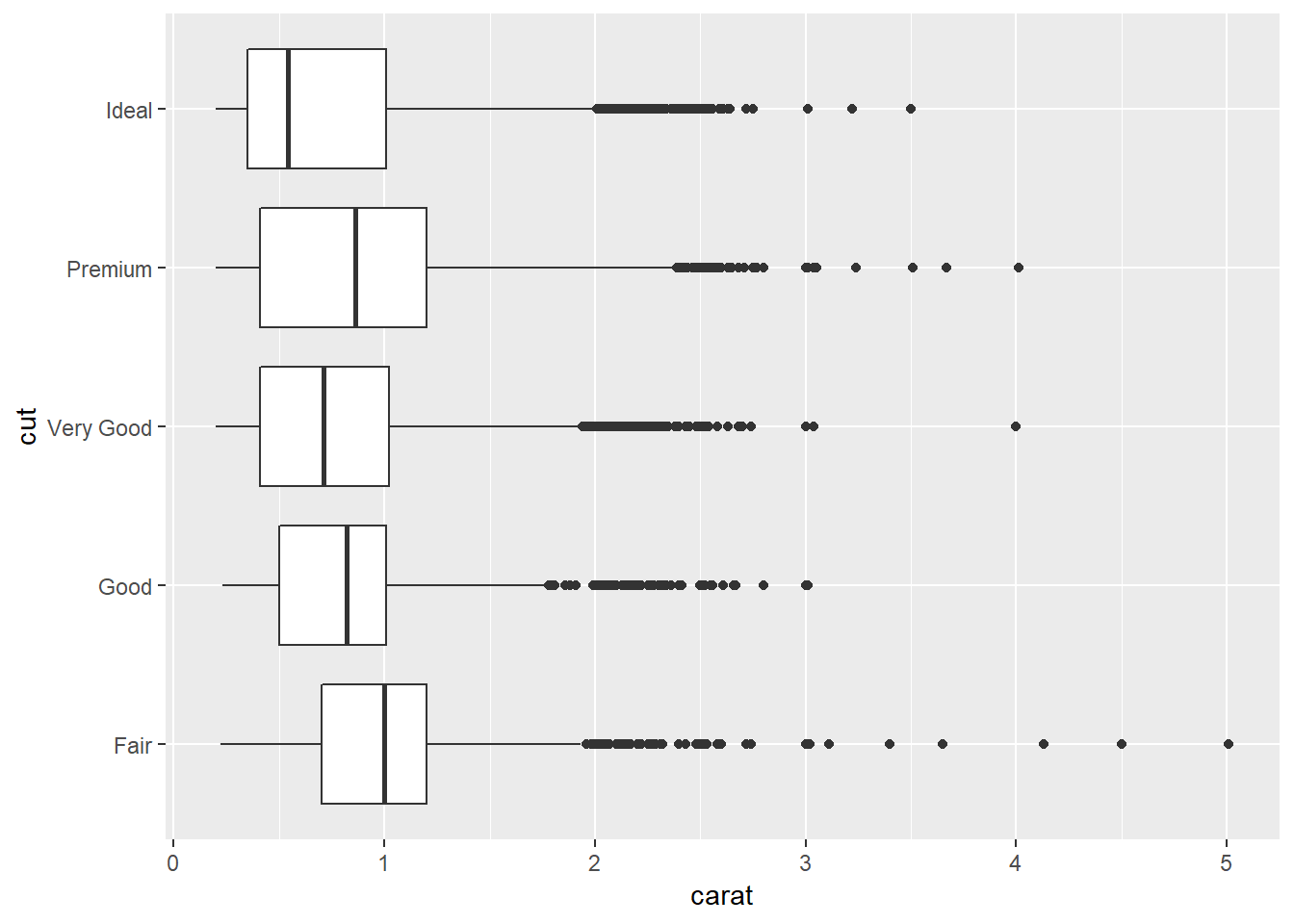
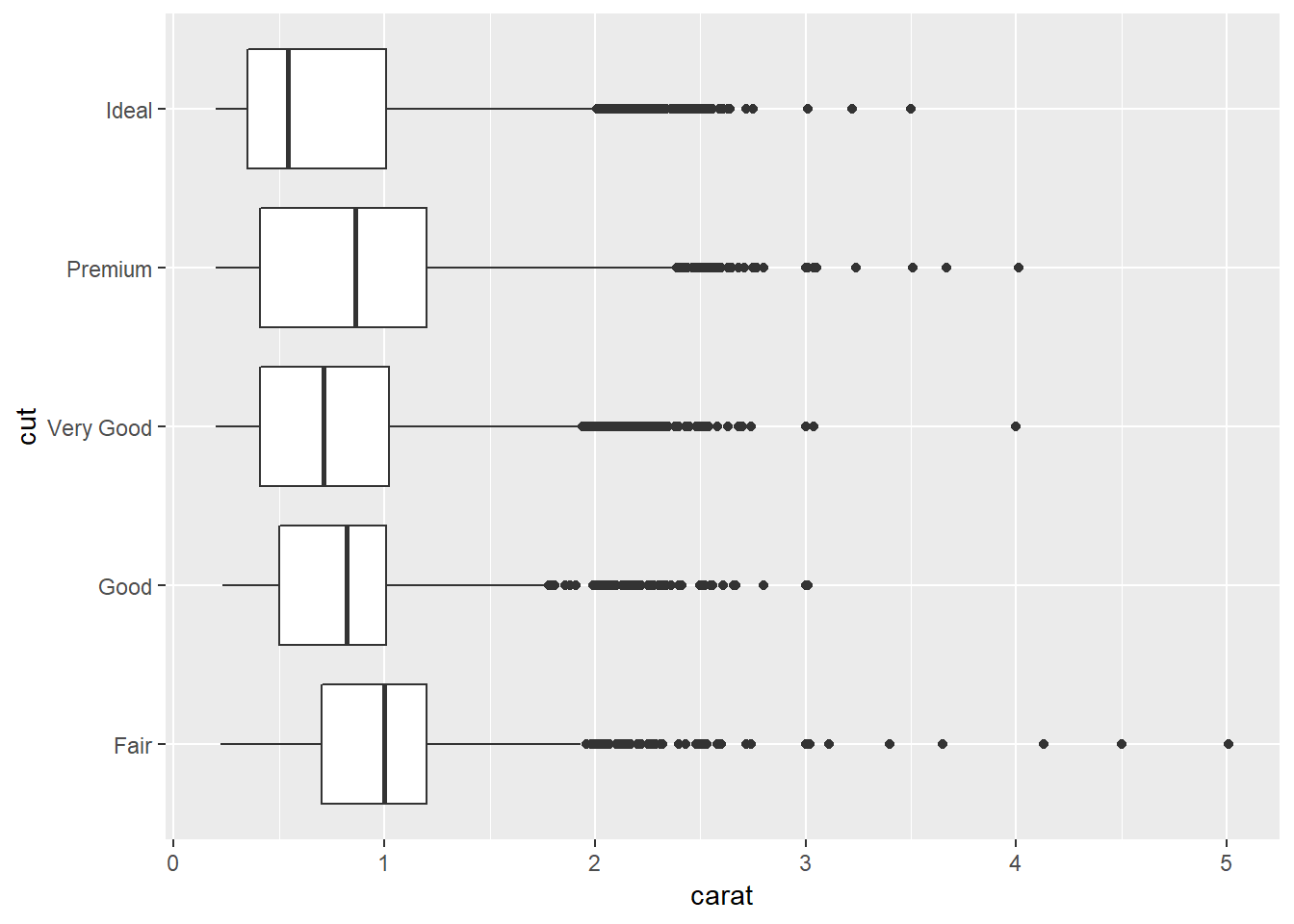
- Looks like it does the exact same thing as flipping
xandyand usingcoord_flip()
4. One problem with boxplots is that they were developed in an era of much smaller datasets and tend to display a prohibitively large number of “outlying values”. One approach to remedy this problem is the letter value plot. Install the lvplot package, and try using geom_lv() to display the distribution of price vs cut. What do you learn? How do you interpret the plots?
I found this helpful
This produces a ‘letter-value’ boxplot which means that in the first box you have the middle ~1/2 of data, then in the adoining boxes the next ~1/4, so within the middle 3 boxes you have the middle ~3/4 of data, next two boxes is ~7/8ths, then ~15/16th etc.
set.seed(1234)
a <- diamonds %>%
ggplot()+
lvplot::geom_lv(aes(x = cut, y = price))
set.seed(1234)
b <- diamonds %>%
ggplot()+
geom_boxplot(aes(x = cut, y = price))Perhaps a helpful way to understand this is to see what it looks like at different specified ‘k’ values (which)
You can see the letters when you add fill = ..LV.. to the aesthetic.
diamonds %>%
ggplot()+
lvplot::geom_lv(aes(x = cut, y = price, alpha = ..LV..), fill = "blue")+
scale_alpha_discrete(range = c(0.7, 0))## Warning: Using alpha for a discrete variable is not advised.diamonds %>%
ggplot()+
lvplot::geom_lv(aes(x = cut, y = price, fill = ..LV..))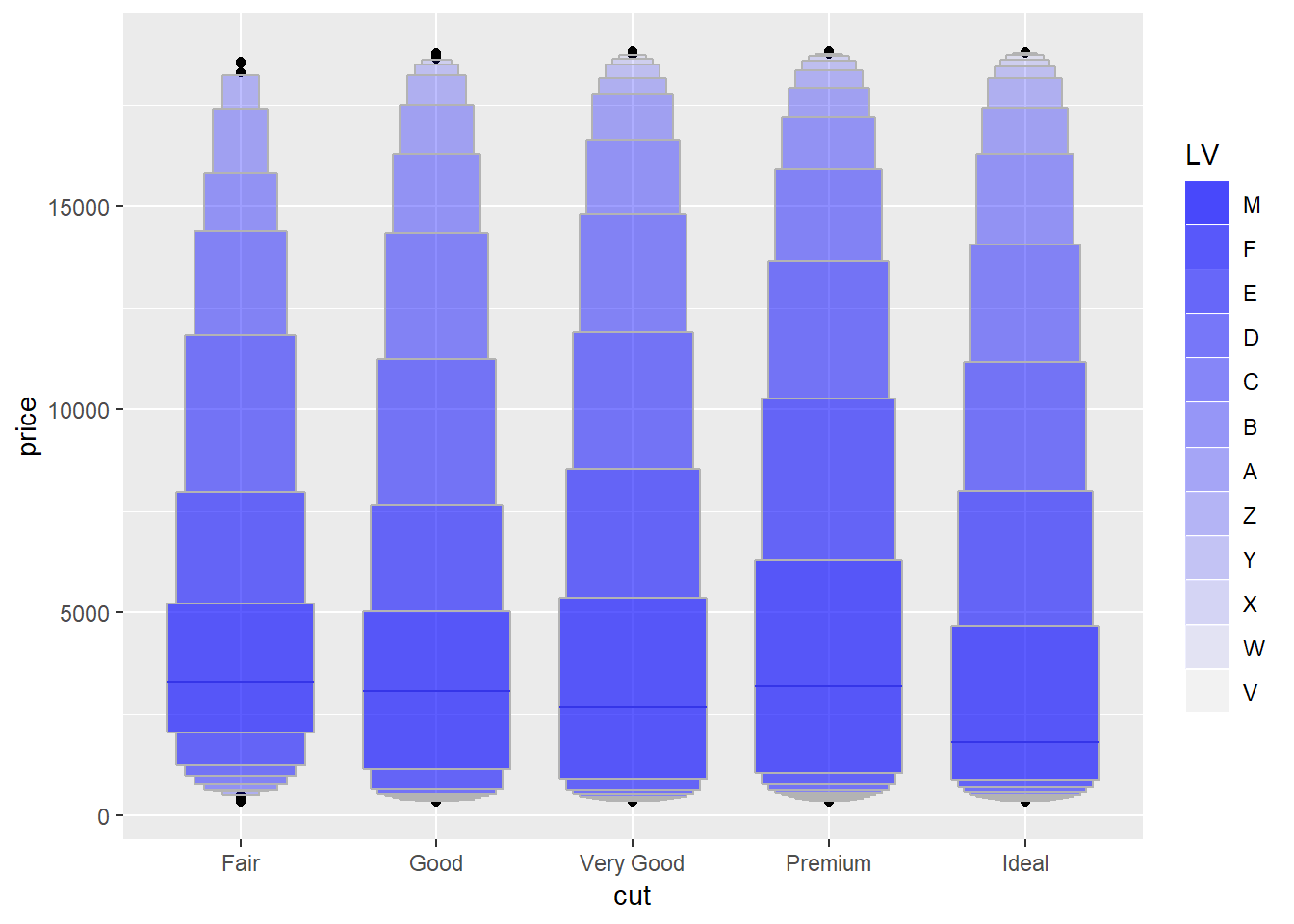
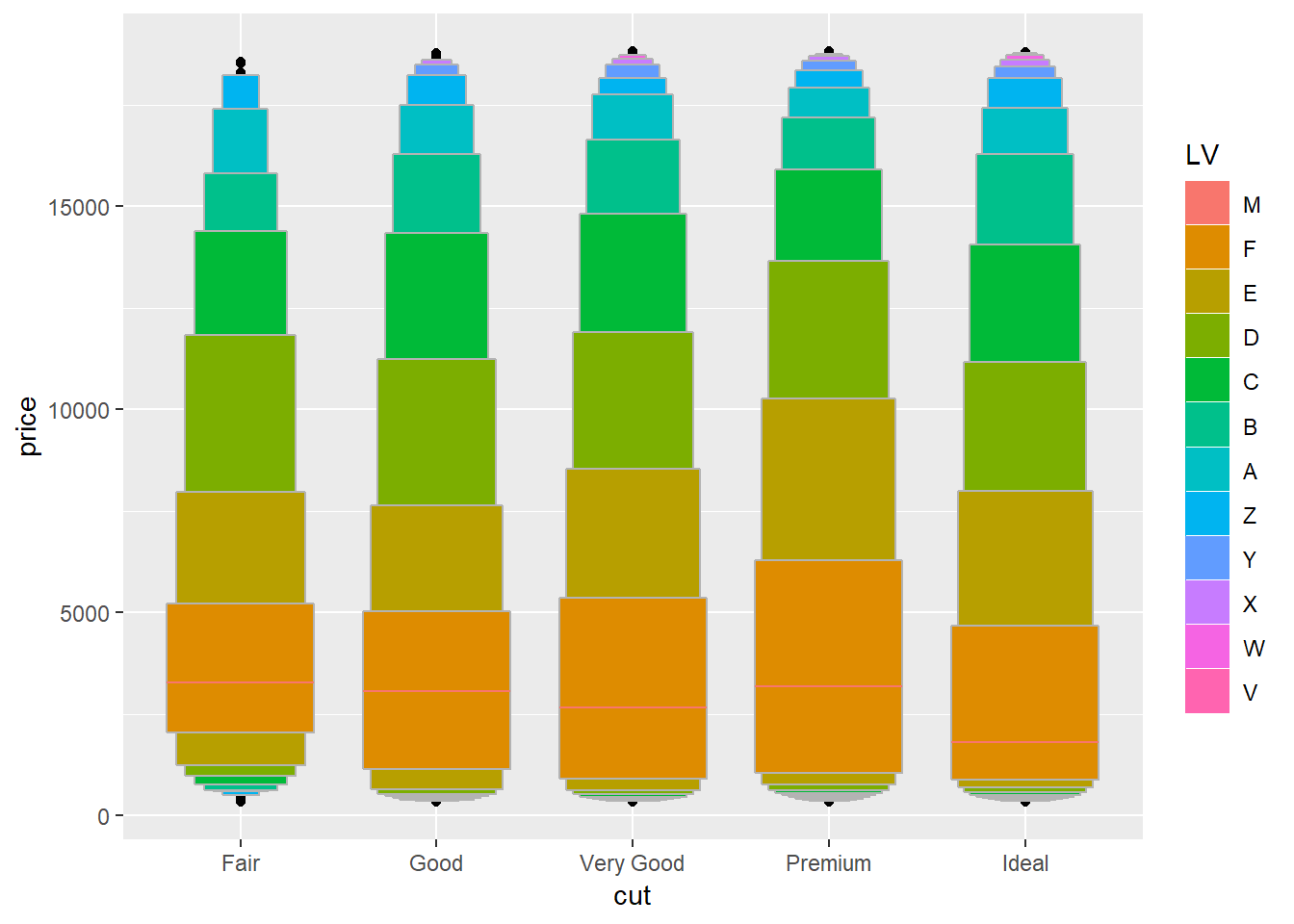
Letters represent ‘median’, ‘fourths’, ‘eights’…
5. Compare and contrast geom_violin() with a facetted geom_histogram(), or a coloured geom_freqpoly(). What are the pros and cons of each method?
ggplot(diamonds,aes(x = cut, y = carat))+
geom_violin()
ggplot(diamonds,aes(colour = cut, x = carat, y = ..density..))+
geom_freqpoly()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.ggplot(diamonds, aes(x = carat, y = ..density..))+
geom_histogram()+
facet_wrap(~cut)## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.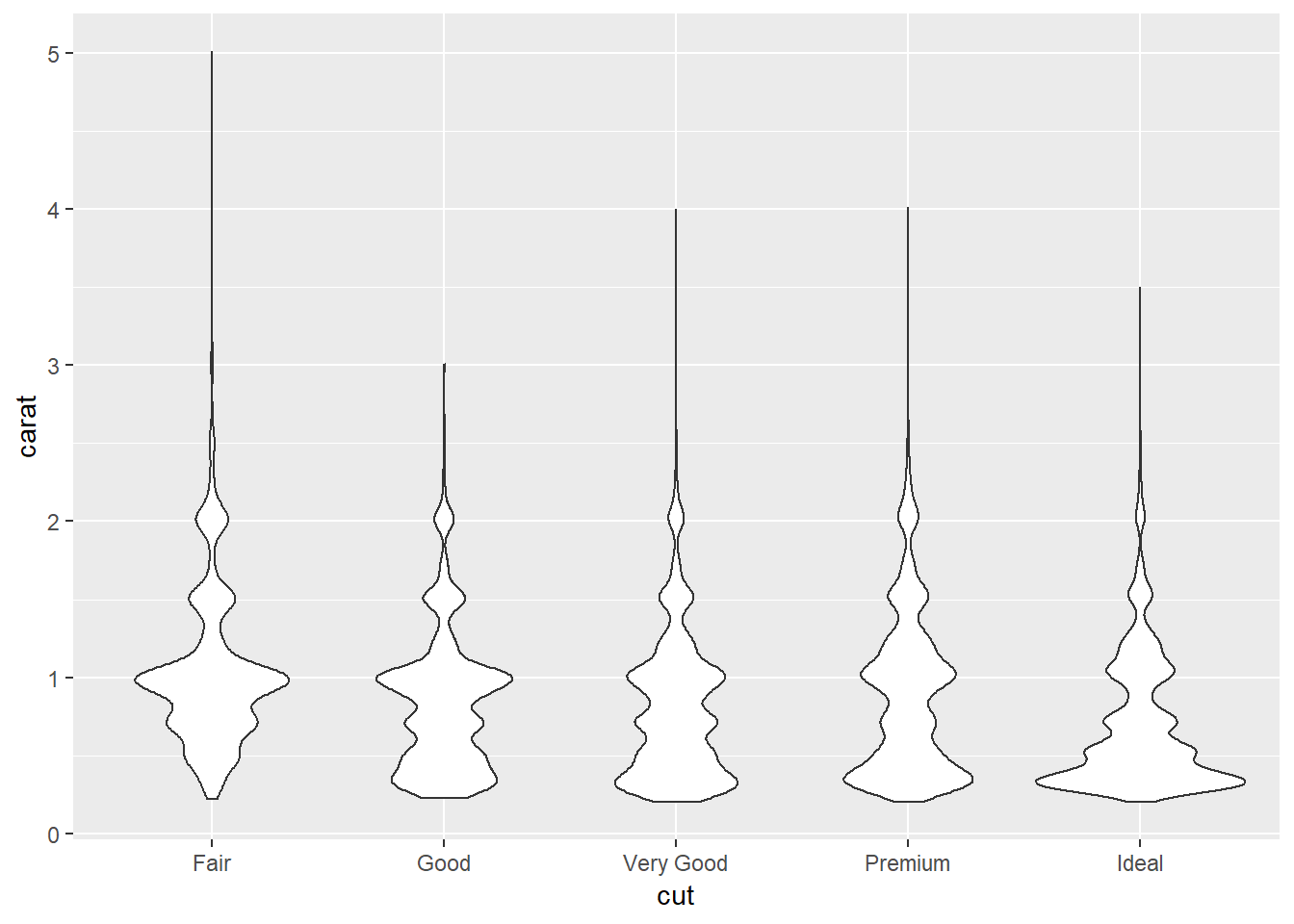
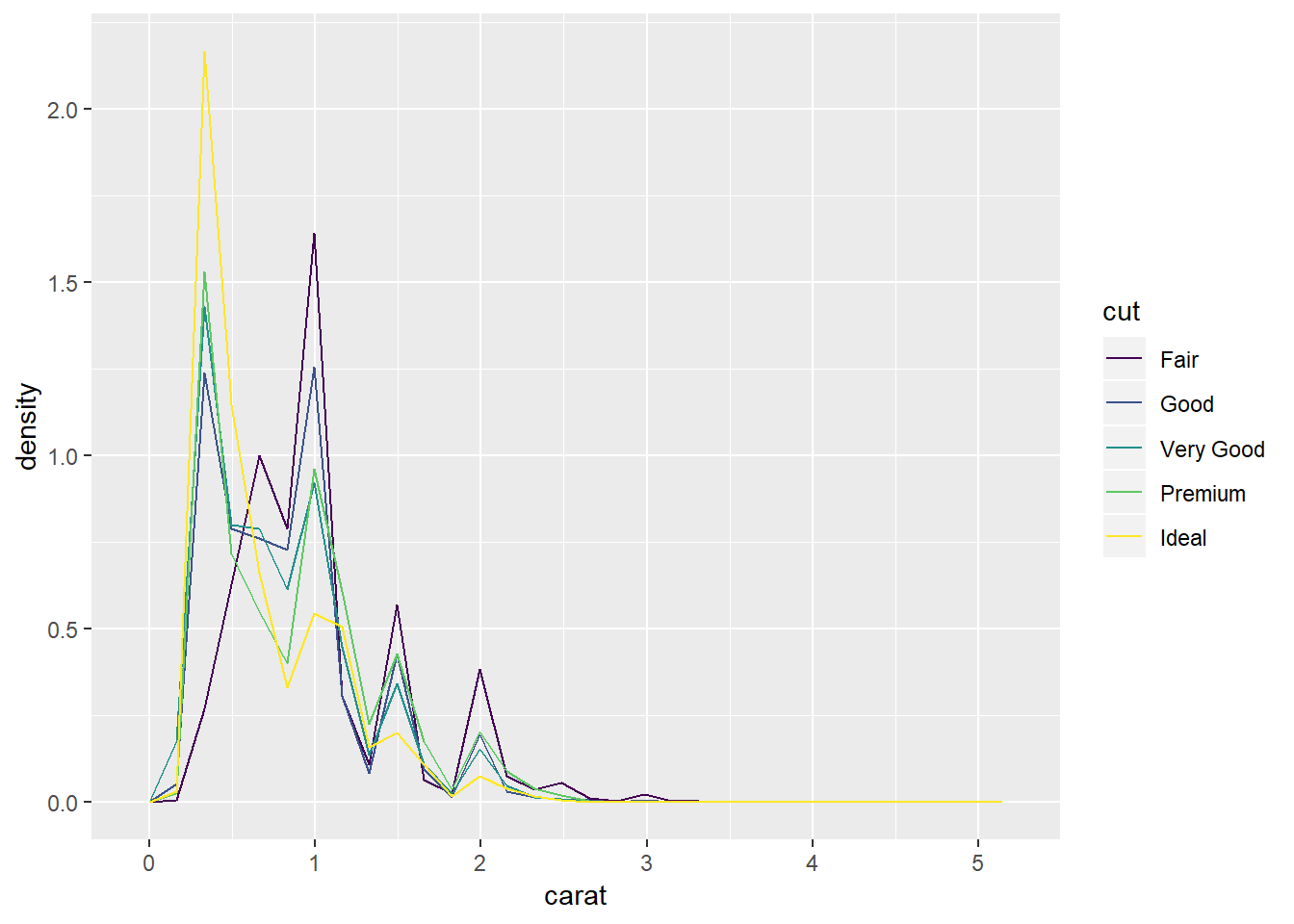
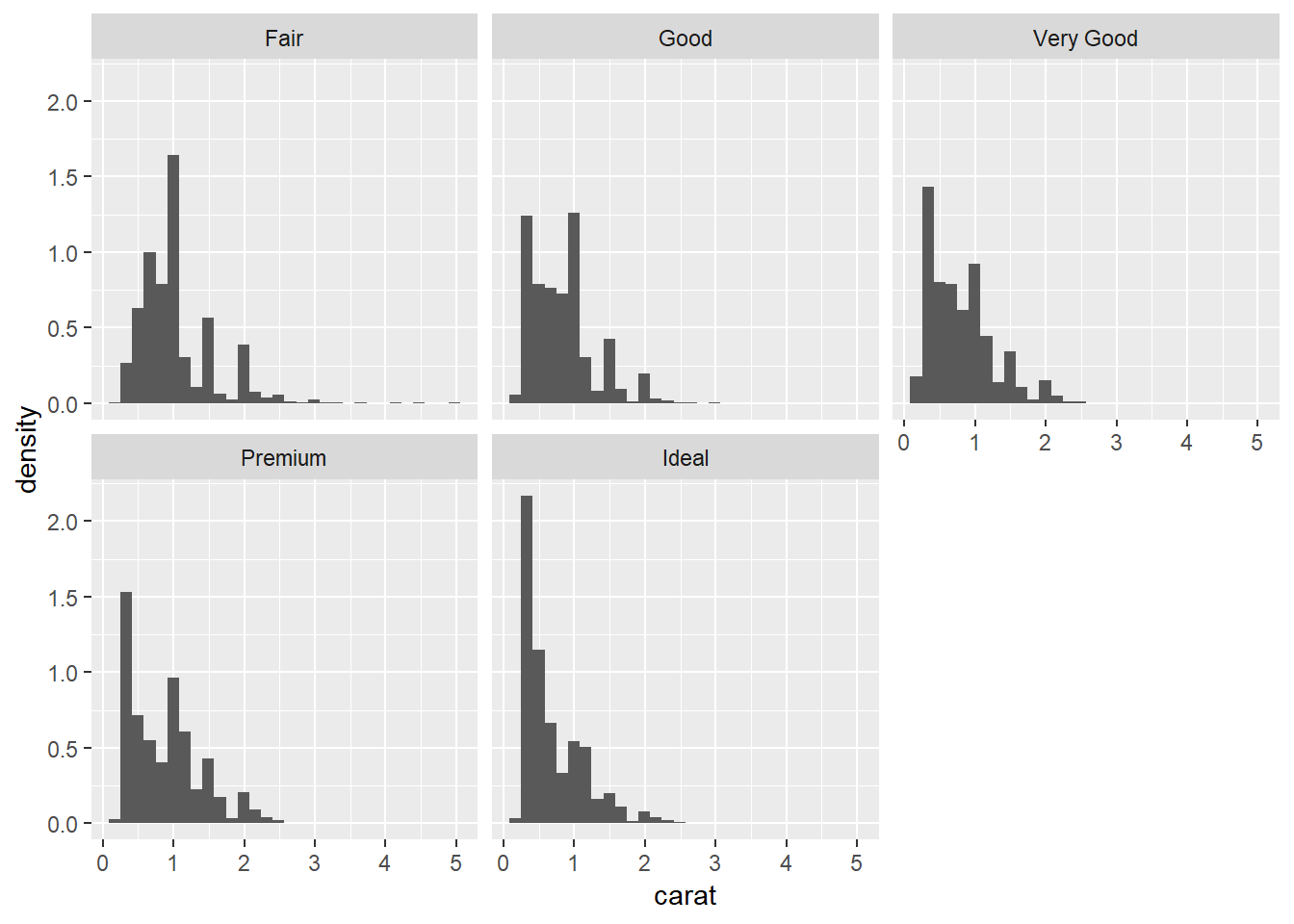
I like how geom_freqpoly has points directly overlaying but it can also be tough to read some, and the lines can overlap and be tough to tell apart, you also have to specify density for this and geom_histogram whereas for geom_violin it is the default. The tails in geom_violin can be easy to read but they also pull these for each of the of the values whereas by faceting geomo_histogram and setting scales = "free" you can have independent scales. I think the biggest advantage of the histogram is that it is the most familiar so people will know what you’re looking at.
6. If you have a small dataset, it’s sometimes useful to use geom_jitter() to see the relationship between a continuous and categorical variable. The ggbeeswarm package provides a number of methods similar to geom_jitter(). List them and briefly describe what each one does.
ggplot(mpg, aes(x = displ, y = cty, color = drv))+
geom_point()
ggplot(mpg, aes(x = displ, y = cty, color = drv))+
geom_jitter()
ggplot(mpg, aes(x = displ, y = cty, color = drv))+
geom_beeswarm()## Warning in f(...): The default behavior of beeswarm has changed in version
## 0.6.0. In versions <0.6.0, this plot would have been dodged on the y-
## axis. In versions >=0.6.0, grouponX=FALSE must be explicitly set to group
## on y-axis. Please set grouponX=TRUE/FALSE to avoid this warning and ensure
## proper axis choice.ggplot(mpg, aes(x = displ, y = cty, color = drv))+
geom_quasirandom()## Warning in f(...): The default behavior of beeswarm has changed in version
## 0.6.0. In versions <0.6.0, this plot would have been dodged on the y-
## axis. In versions >=0.6.0, grouponX=FALSE must be explicitly set to group
## on y-axis. Please set grouponX=TRUE/FALSE to avoid this warning and ensure
## proper axis choice.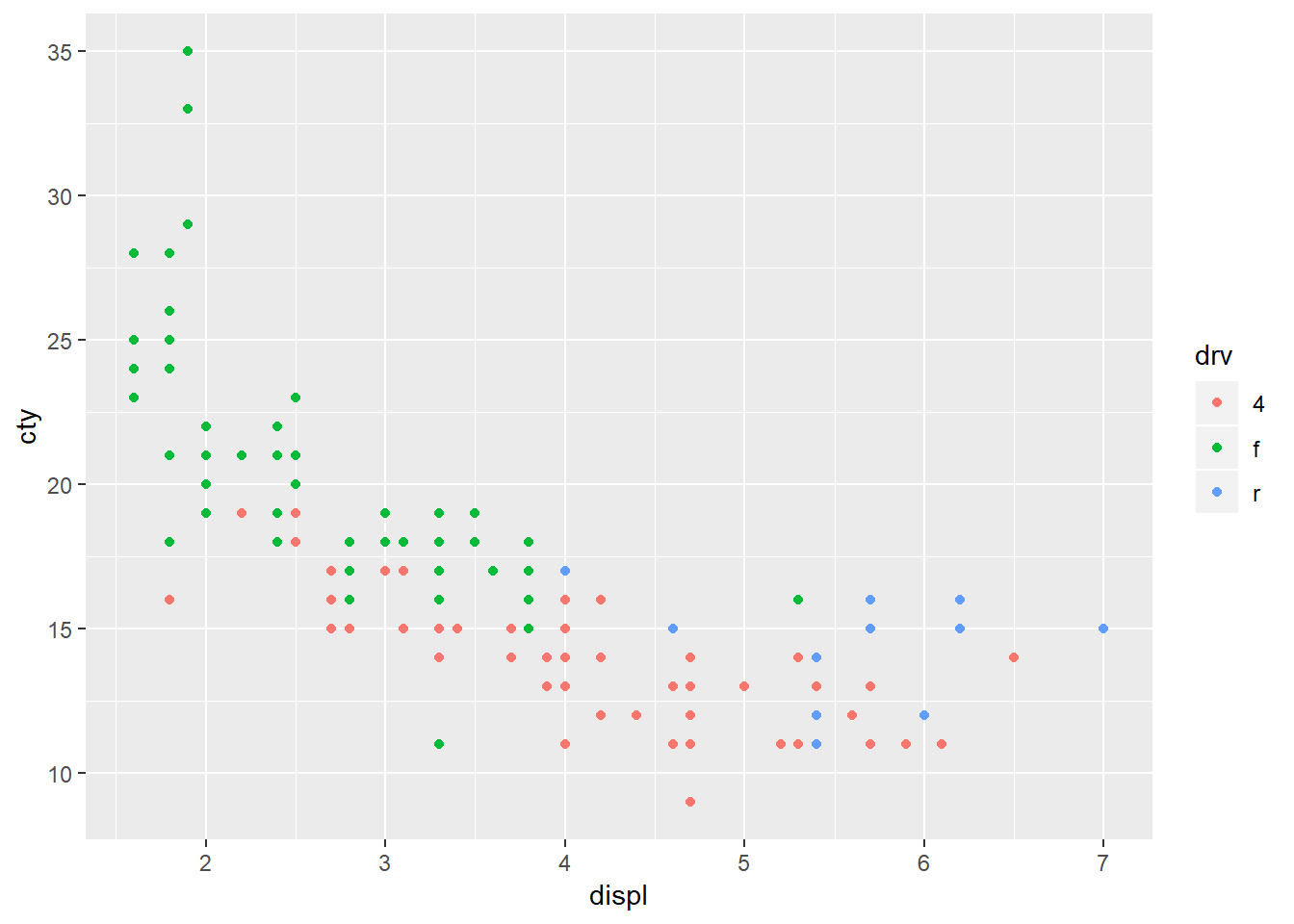
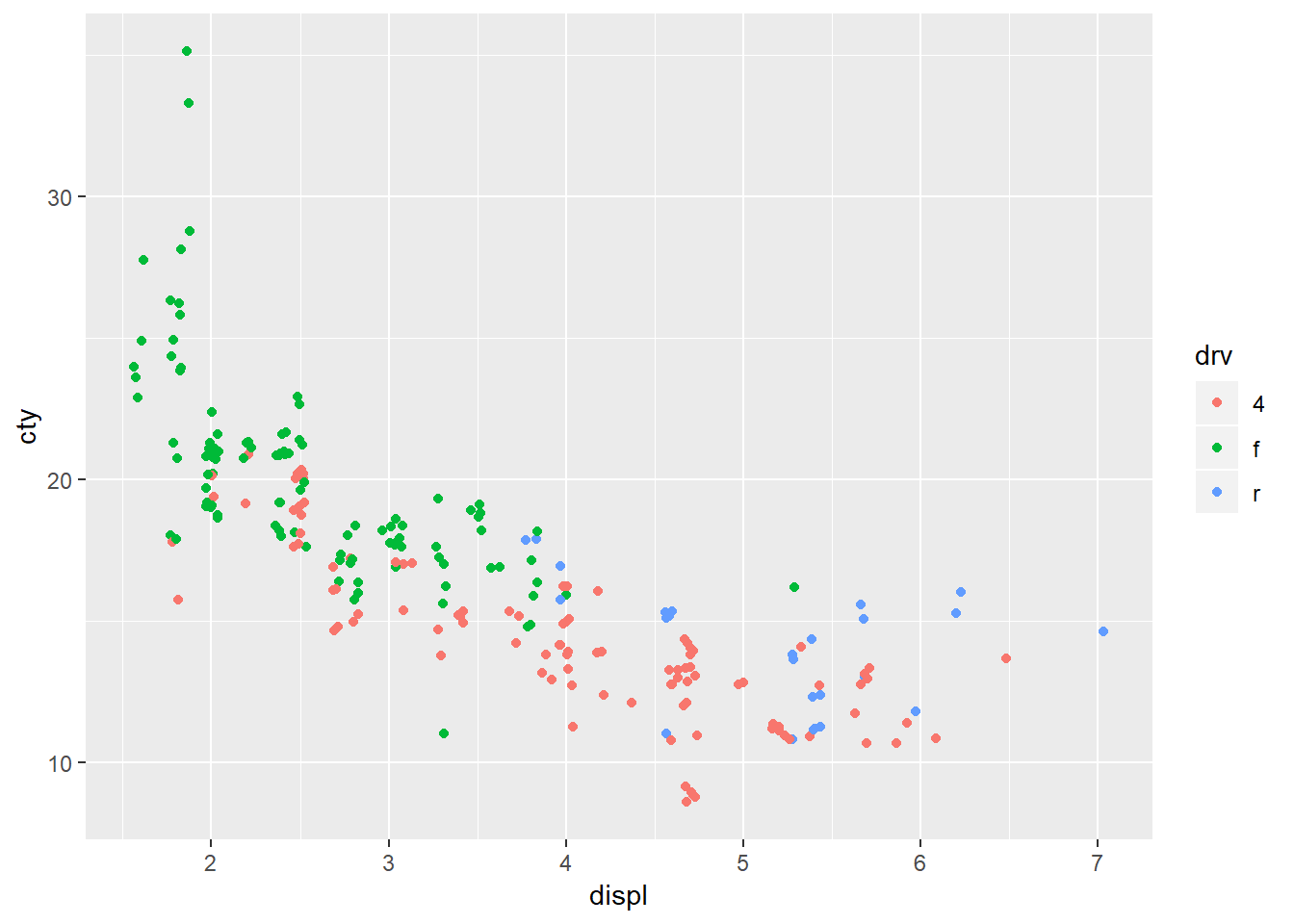
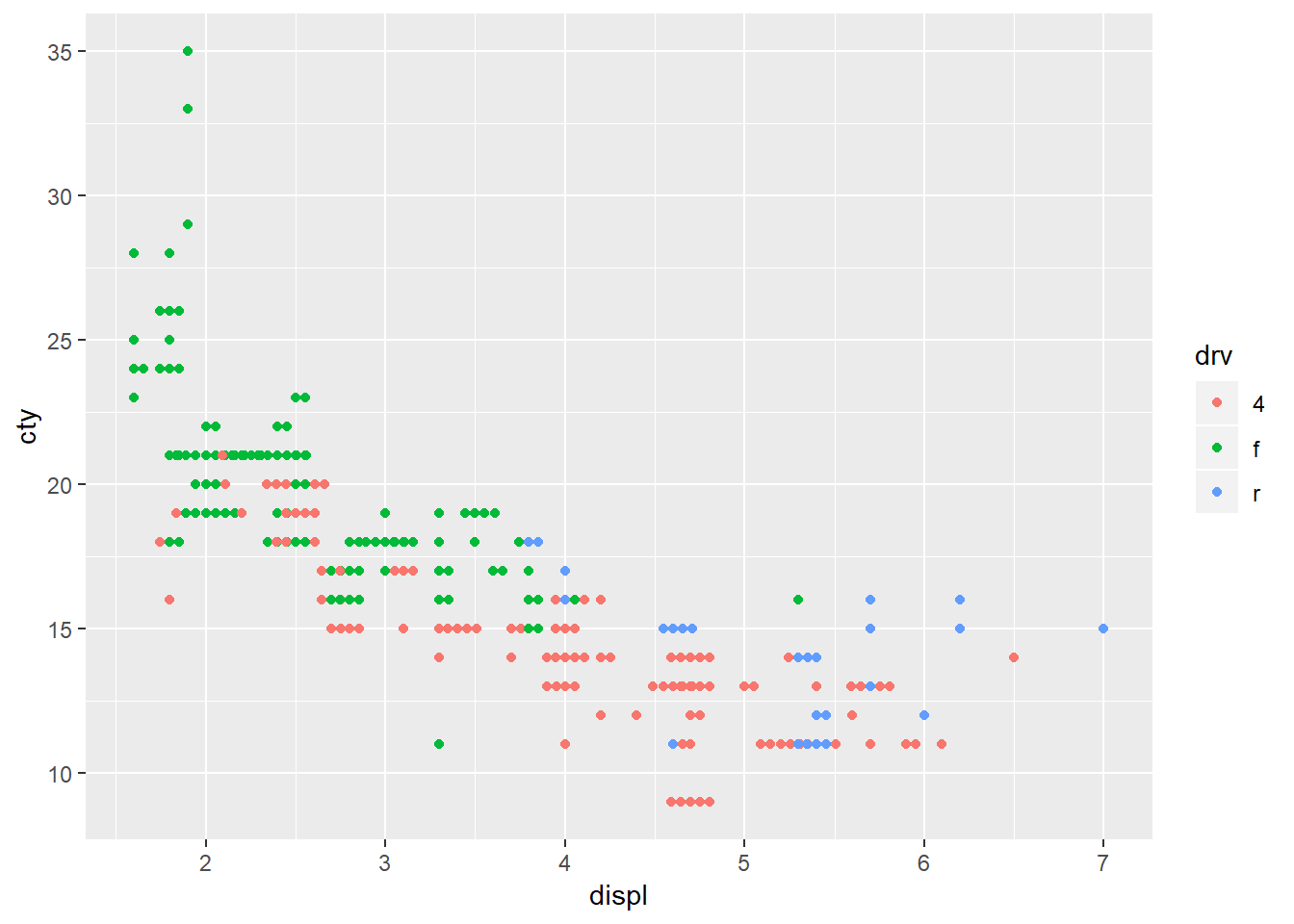
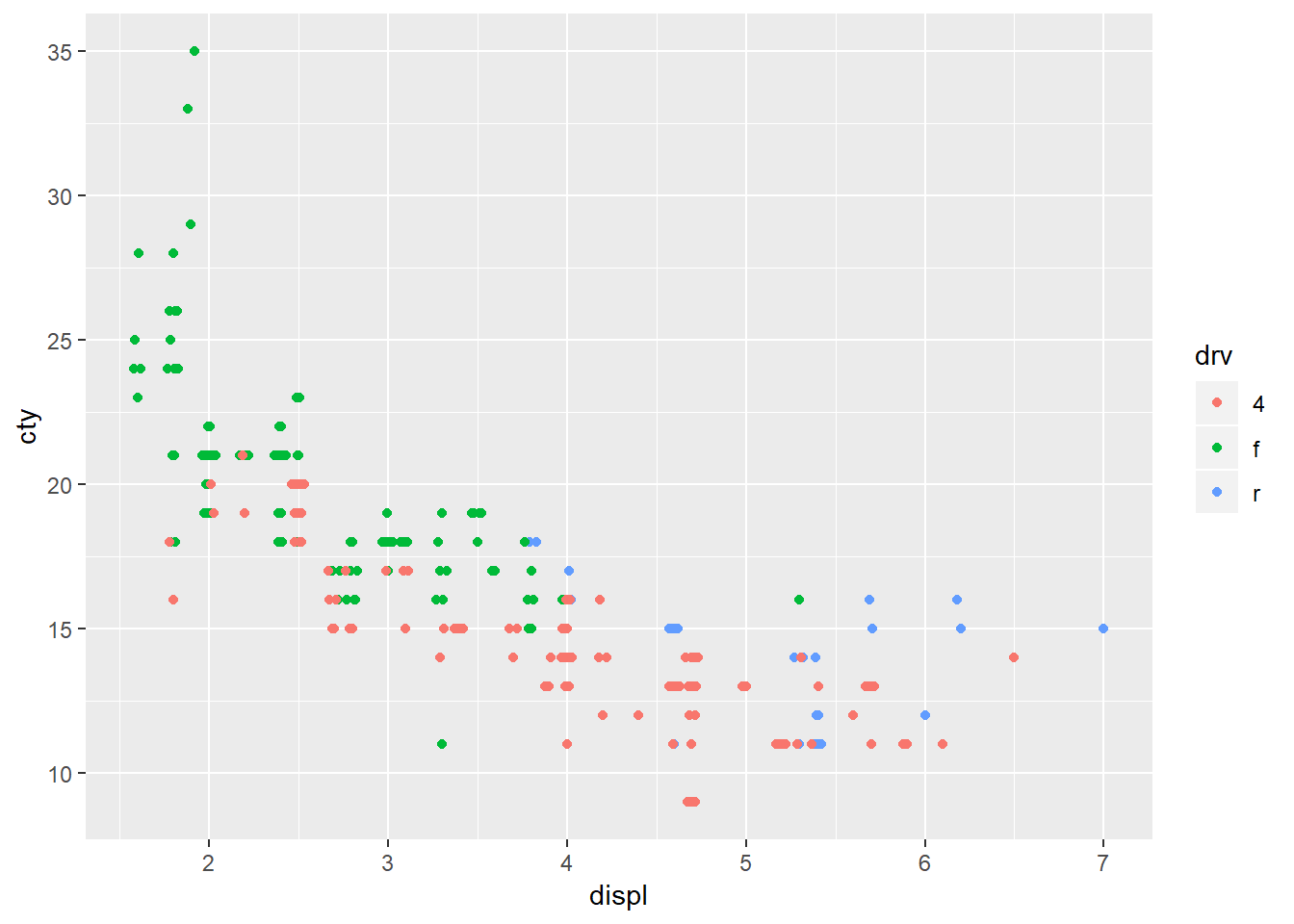
geom_jitter is similar to geom_point but it provides random noise to the points. You can control these with the width and height arguments. This is valuable as it allows you to better see points that may overlap one another. geom_beeswarm adds variation in a uniform pattern by default across only the x-axis. geom-quasirandom also defaults to distributing the points across the x-axis however it produces quasi-random variation, ‘quasi’ because it looks as though points follow some interrelationship21 and if you run the plot multiple times you will get the exact same plot whereas for geom_jitter you will get a slightly different plot each time. To see the differences between geom_beeswarm and geom_quasirandom` it’s helpful to look at the plots above, but holding the y value constant at 1.
plot_orig <- ggplot(mpg, aes(x = displ, y = cty, color = drv))+
geom_point()
plot_bees <- ggplot(mpg, aes(x = 1, y = cty, color = drv))+
geom_beeswarm()
plot_quasi <- ggplot(mpg, aes(x = 1, y = cty, color = drv))+
geom_quasirandom()
gridExtra::grid.arrange(plot_orig, plot_bees, plot_quasi, ncol = 1)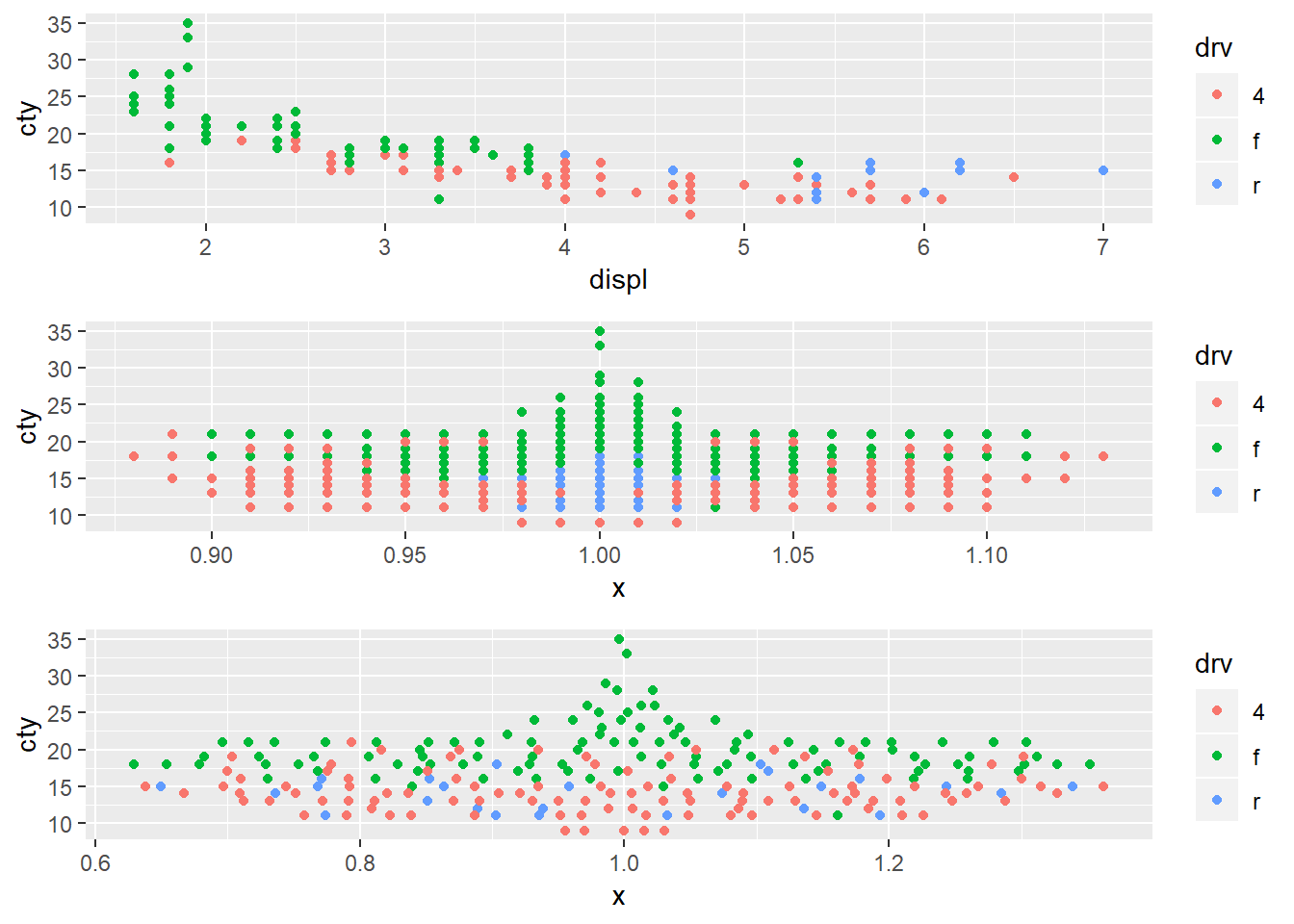
7.5.2.1.
1. How could you rescale the count dataset above to more clearly show the distribution of cut within colour, or colour within cut?
Proportion cut in color: (change group_by() to group_by(cut, color) to set-up the converse)
cut_in_color_graph <- diamonds %>%
group_by(color, cut) %>%
summarise(n = n()) %>%
mutate(proportion_cut_in_color = n/sum(n)) %>%
ggplot(aes(x = color, y = cut))+
geom_tile(aes(fill = proportion_cut_in_color))+
labs(fill = "proportion\ncut in color")
cut_in_color_graph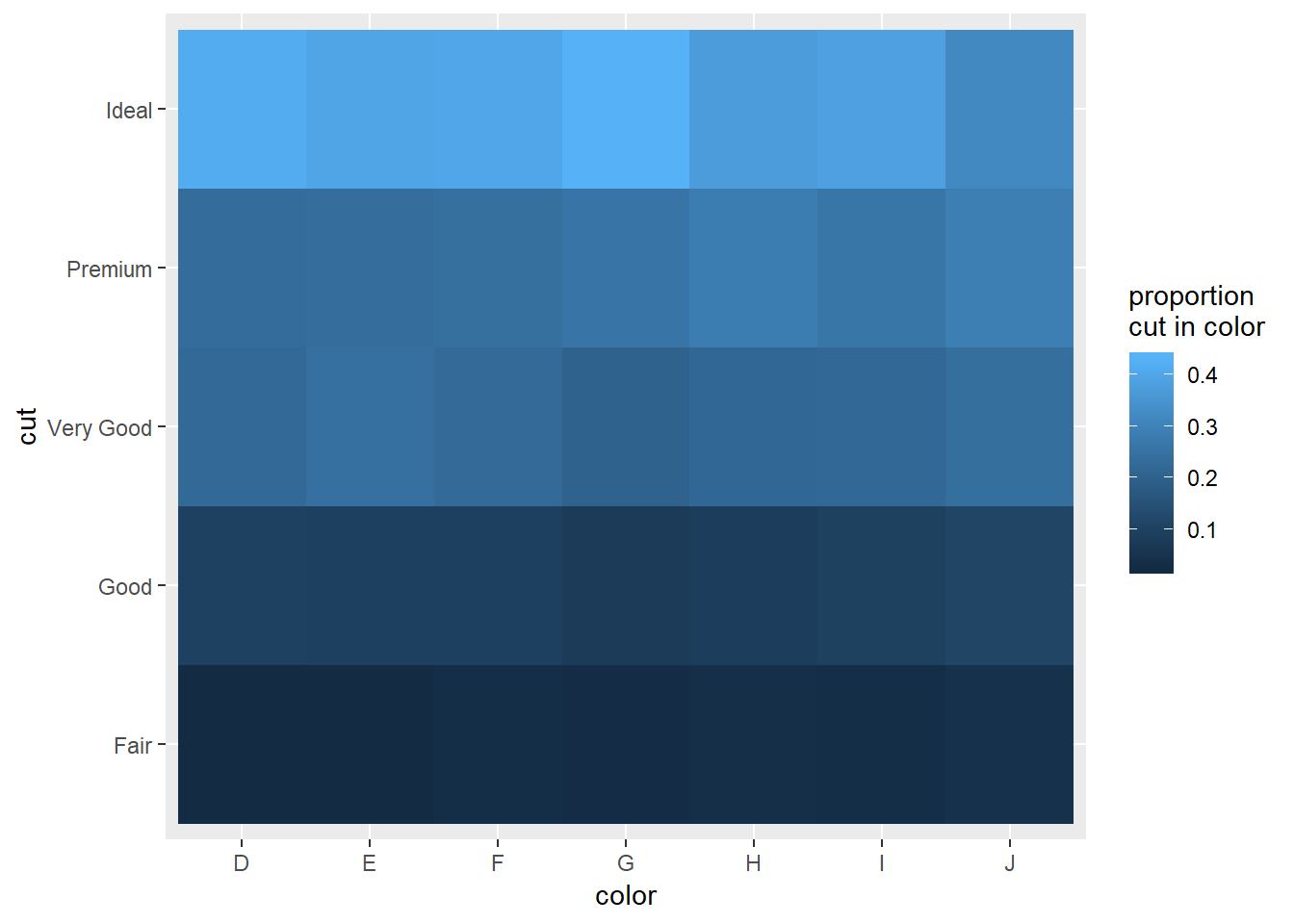
This makes it clear that ideal cuts dominate the proportions of multiple colors, not ust G22
2. Use geom_tile() together with dplyr to explore how average flight delays vary by destination and month of year. What makes the plot difficult to read? How could you improve it?
I improved the original graph by adding in a filter so that only destinations that received over 10000 flights were included:
flights %>%
group_by(dest, month) %>%
summarise(delay_mean = mean(dep_delay, na.rm=TRUE),
n = n()) %>%
mutate(sum_n = sum(n)) %>%
select(dest, month, delay_mean, n, sum_n) %>%
as.data.frame() %>%
filter(dest == "ABQ") %>%
#the sum on n will be at the dest level here
filter(sum_n > 30) %>%
ggplot(aes(x = as.factor(month), y = dest, fill = delay_mean))+
geom_tile()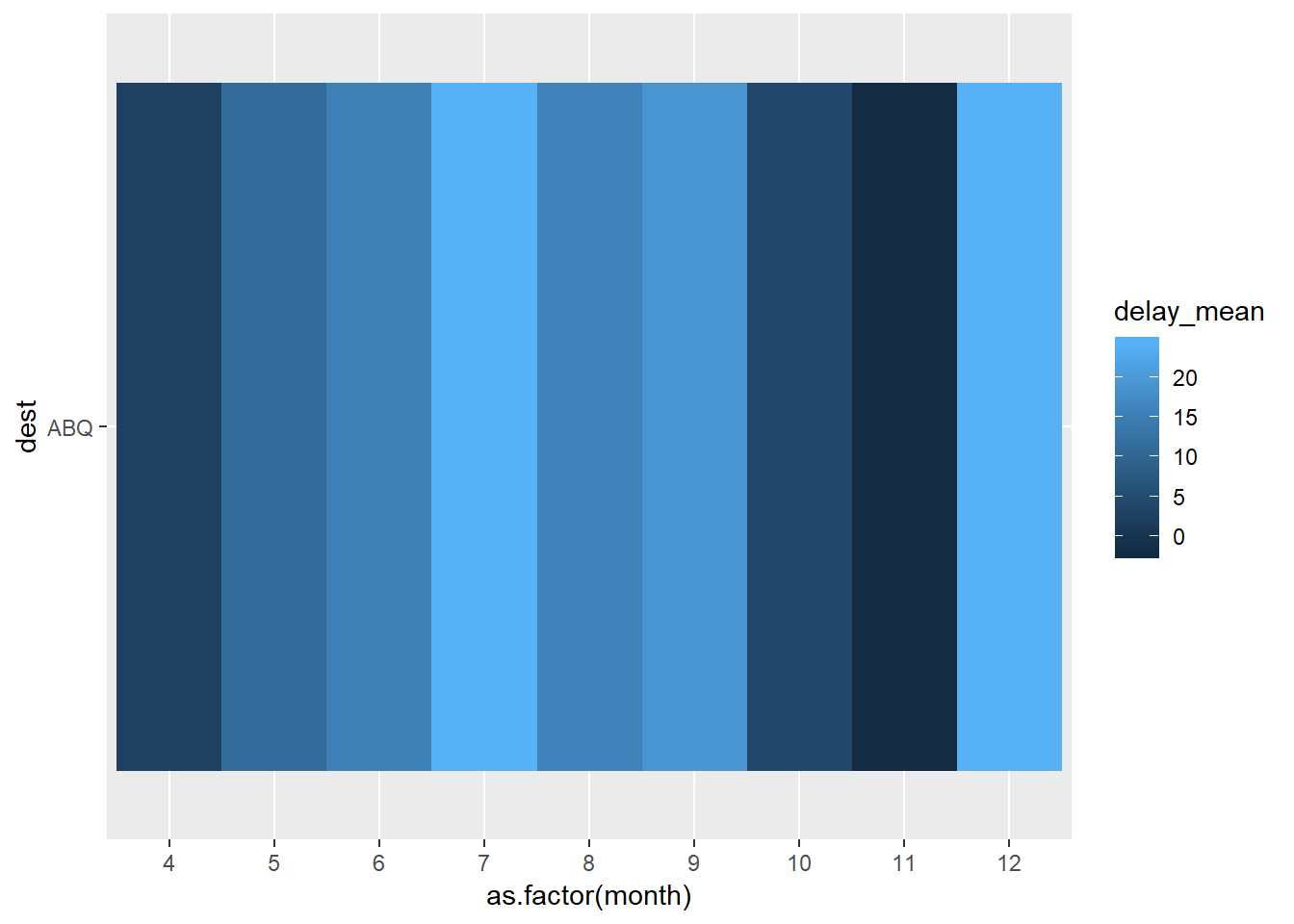
Another way to improve it may be to group the destinations into regions. This also will prevent you from filtering out data. We aren’t given region information, but we do have lat and long points in the airports dataset. See Appendix for notes
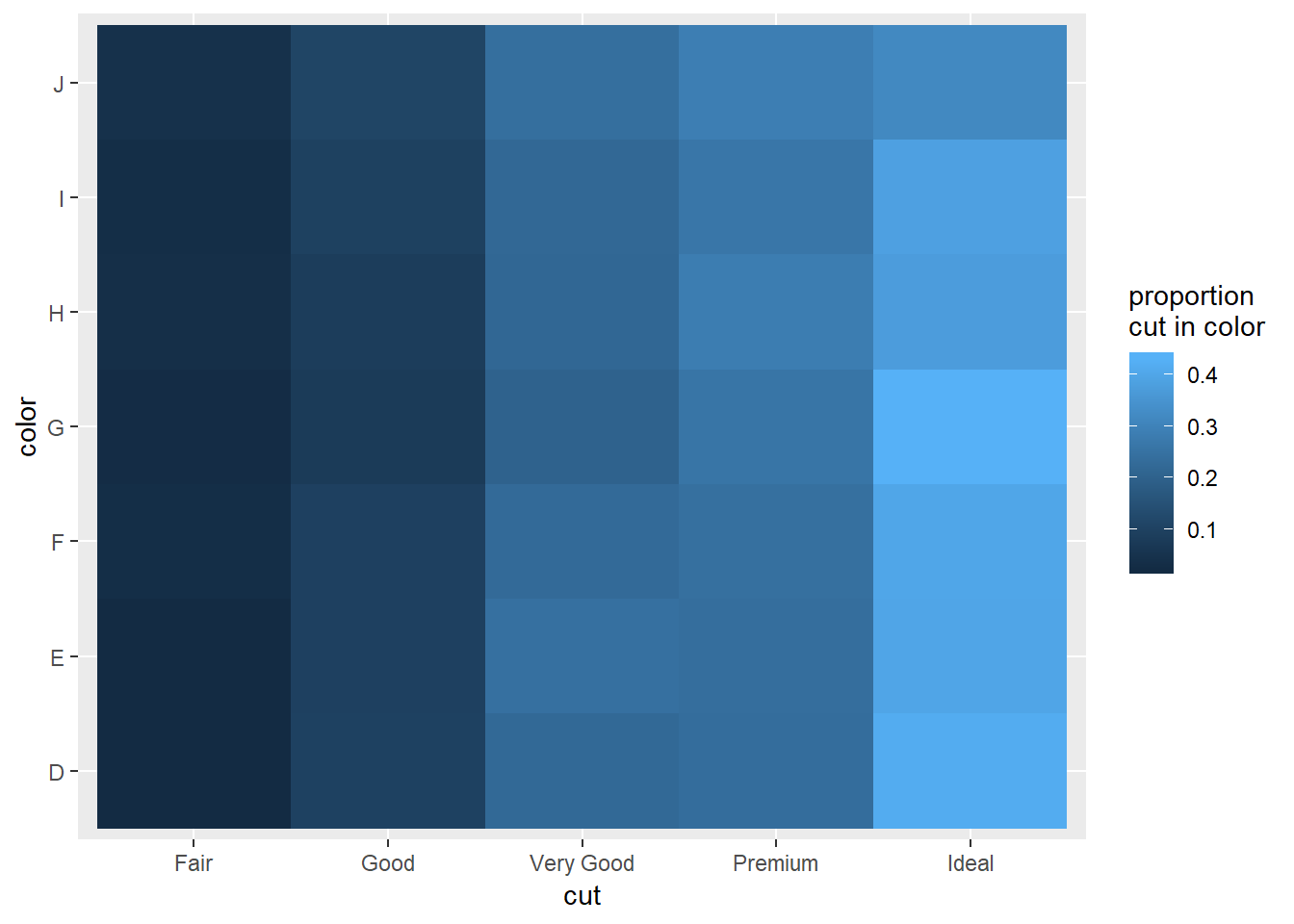
3. Why is it slightly better to use aes(x = color, y = cut) rather than aes(x = cut, y = color) in the example above?
If you’re comparing the proportion of cut in color and want to be looking at how the specific cut proportion is changing, it may easier to view this while looking left to right vs. down to up. Compare the two plots below.
cut_in_color_graph
cut_in_color_graph+
coord_flip()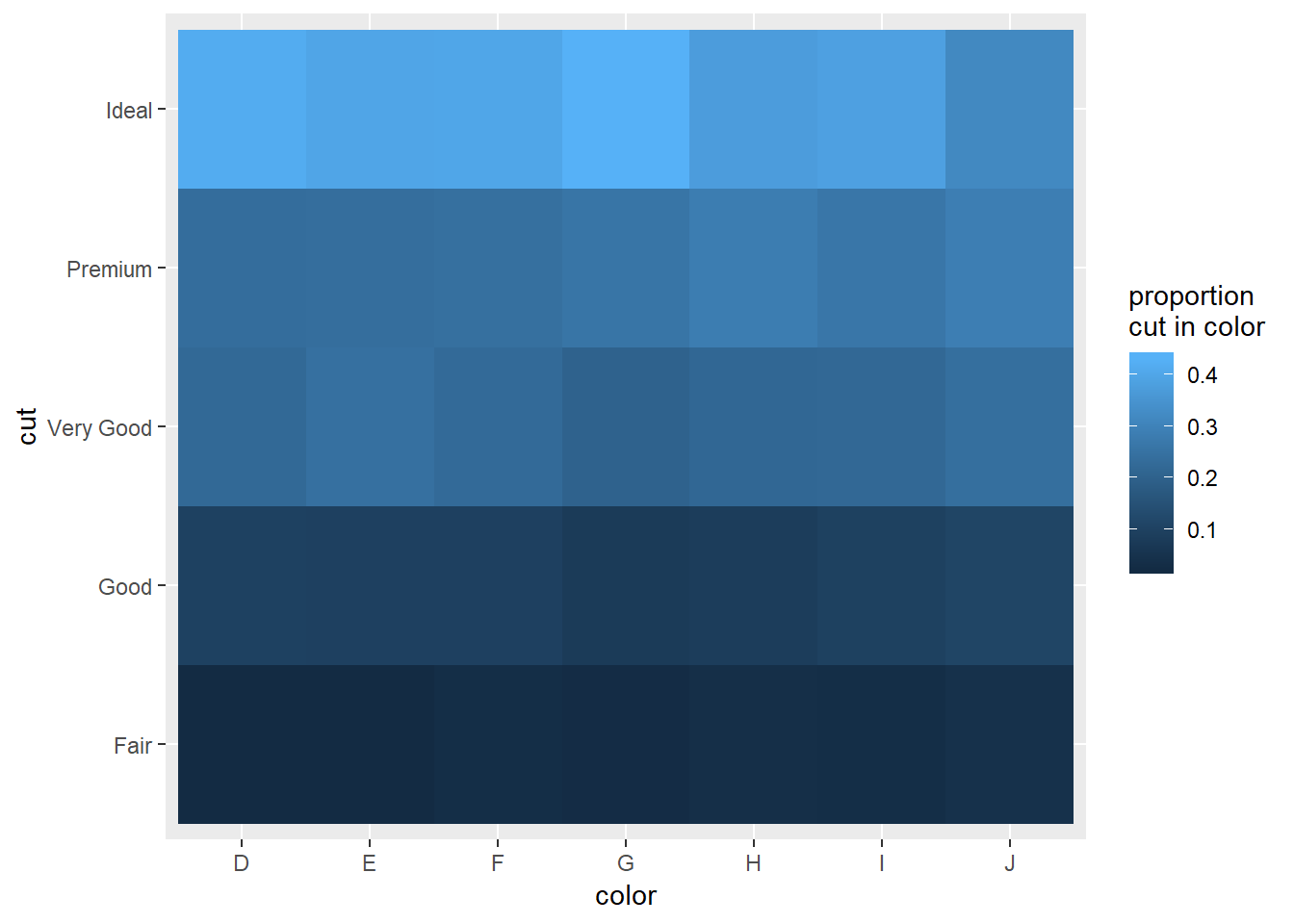
7.5.3.
Two-d histograms
smaller <- diamonds %>%
filter(carat < 3)
ggplot(data = smaller) +
geom_hex(mapping = aes(x = carat, y = price))
#can change bin number
ggplot(data = smaller) +
geom_bin2d(mapping = aes(x = carat, y = price), bins = c(30, 30))
# #or binwidth (roughly equivalent chart would be created)
# ggplot(data = smaller) +
# geom_bin2d(mapping = aes(x = carat, y = price), binwidth = c(.1, 1000))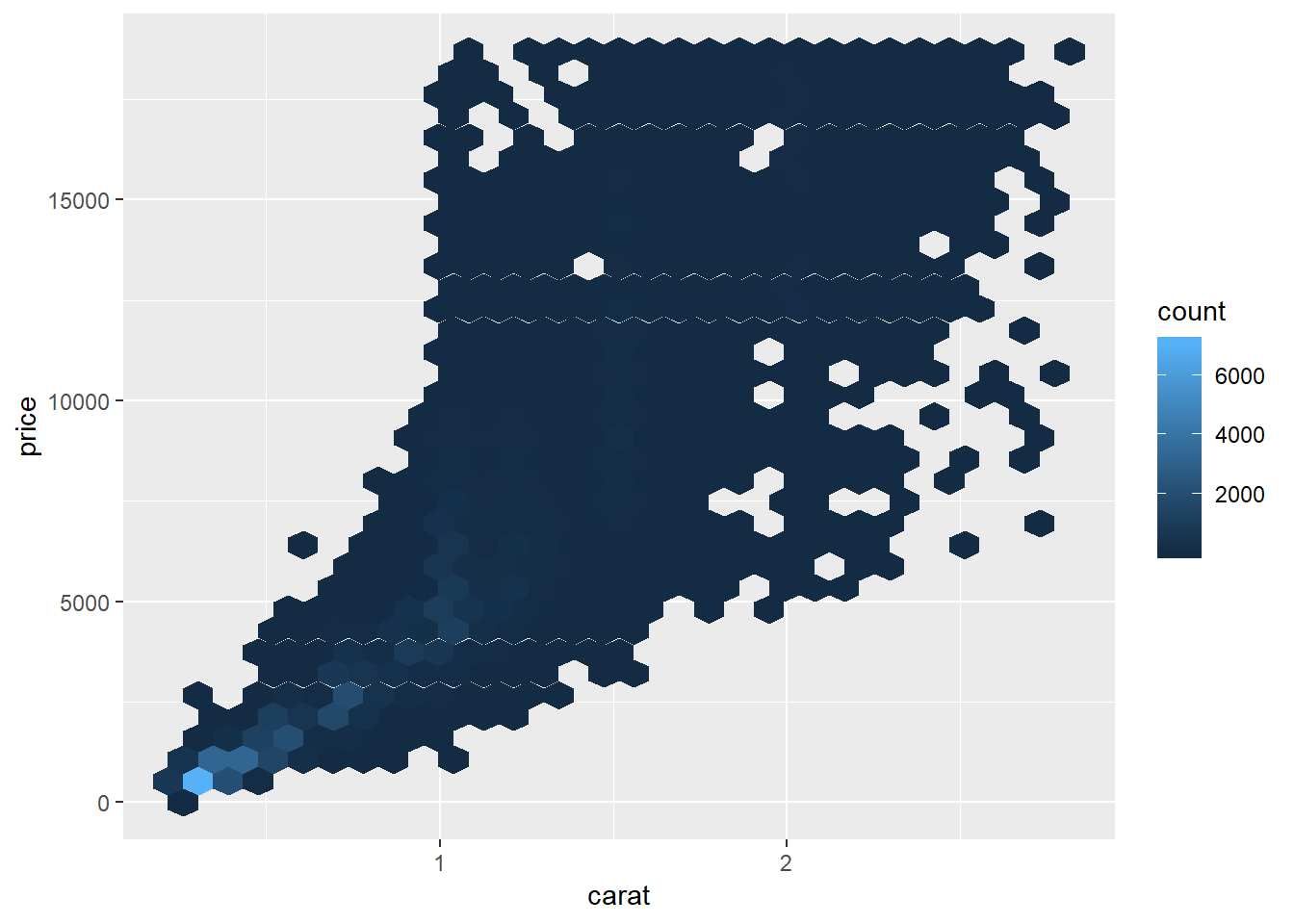
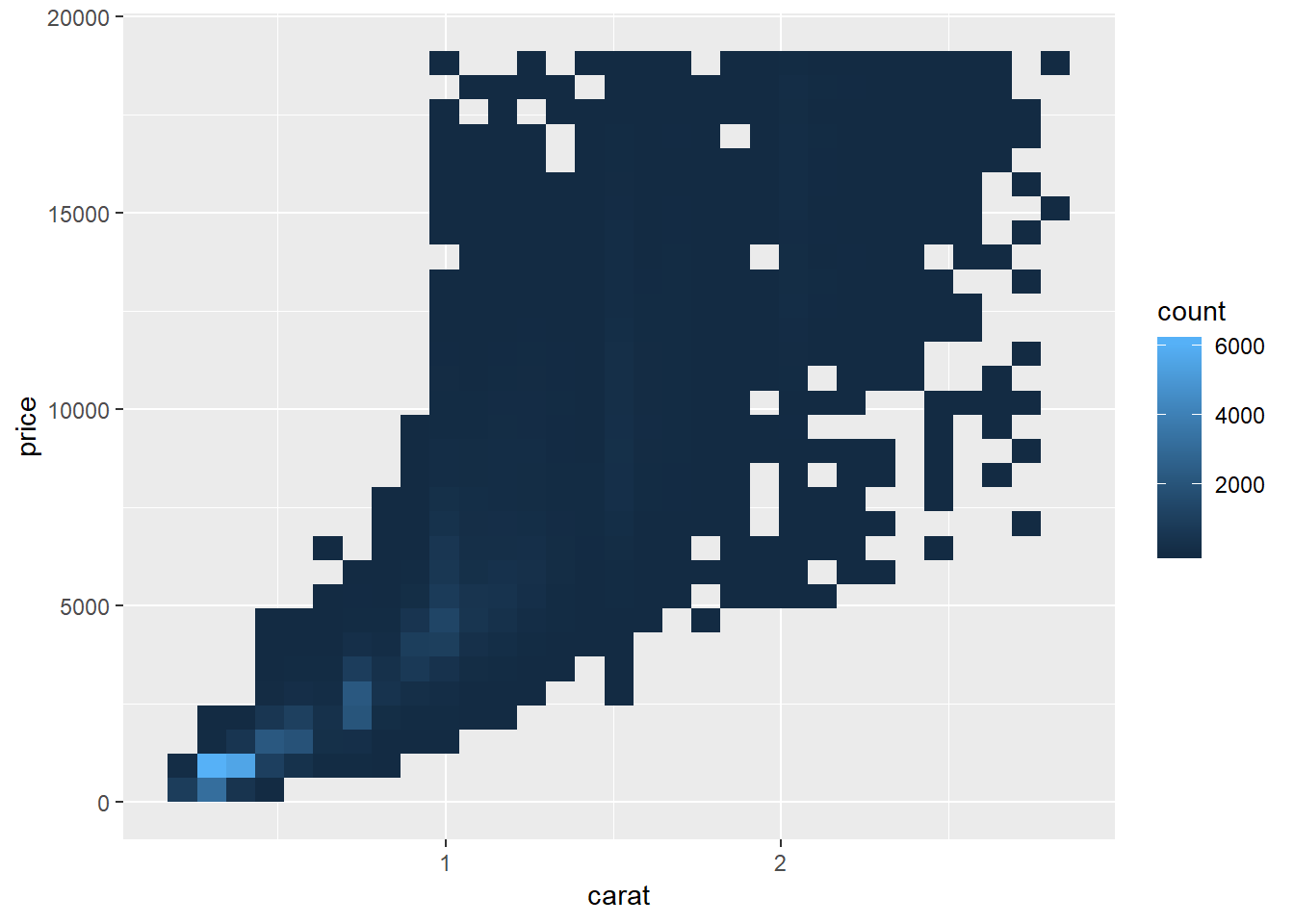
Binned boxplots, violins, and lvs
#split by width
ggplot(smaller, aes(x = carat, y = price))+
geom_boxplot(aes(group = cut_width(carat, 0.1)))
#split to get approximately same number in each box with cut_number()
ggplot(smaller, aes(x = carat, y = price))+
geom_boxplot(aes(group = cut_number(carat, 20)))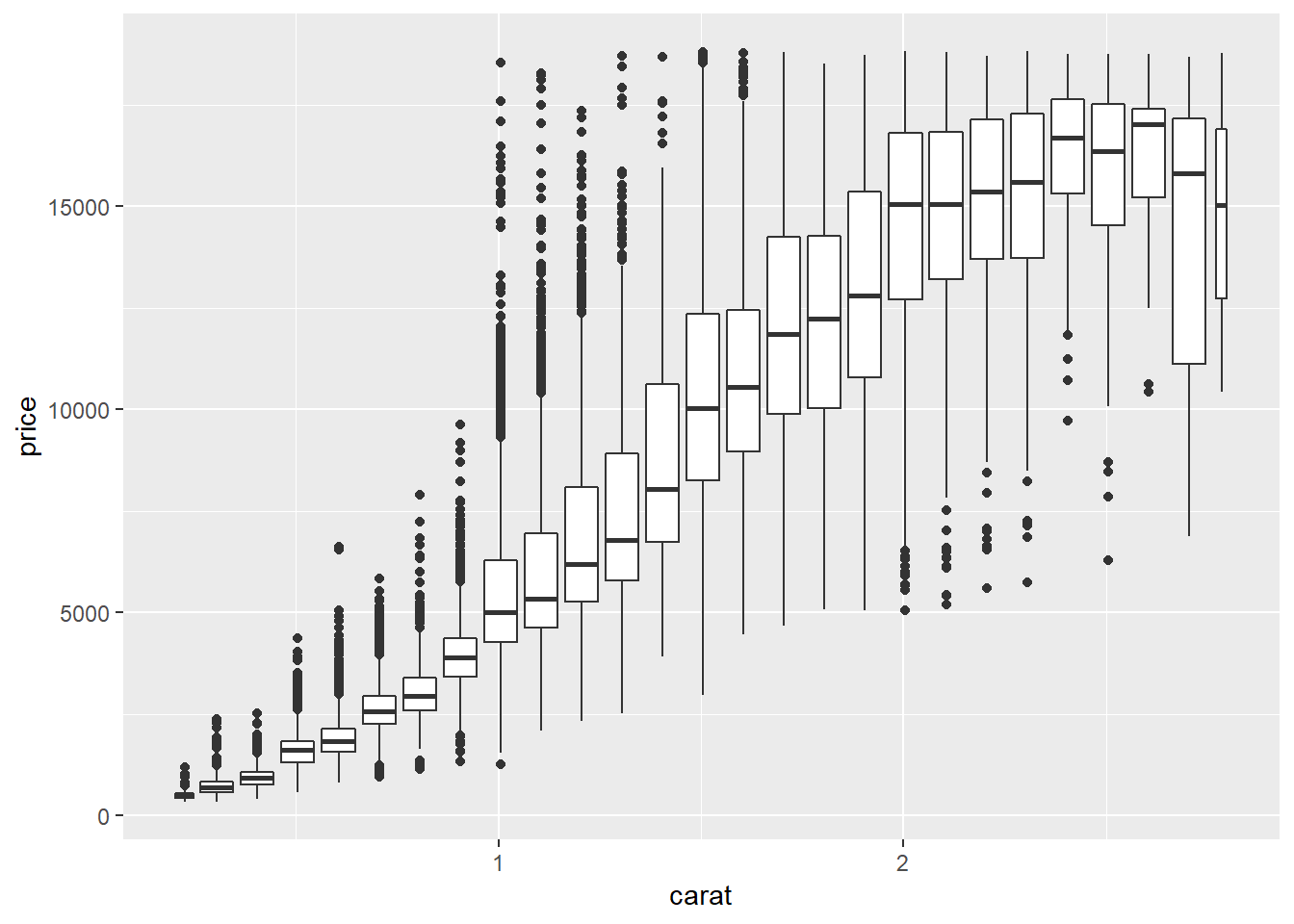
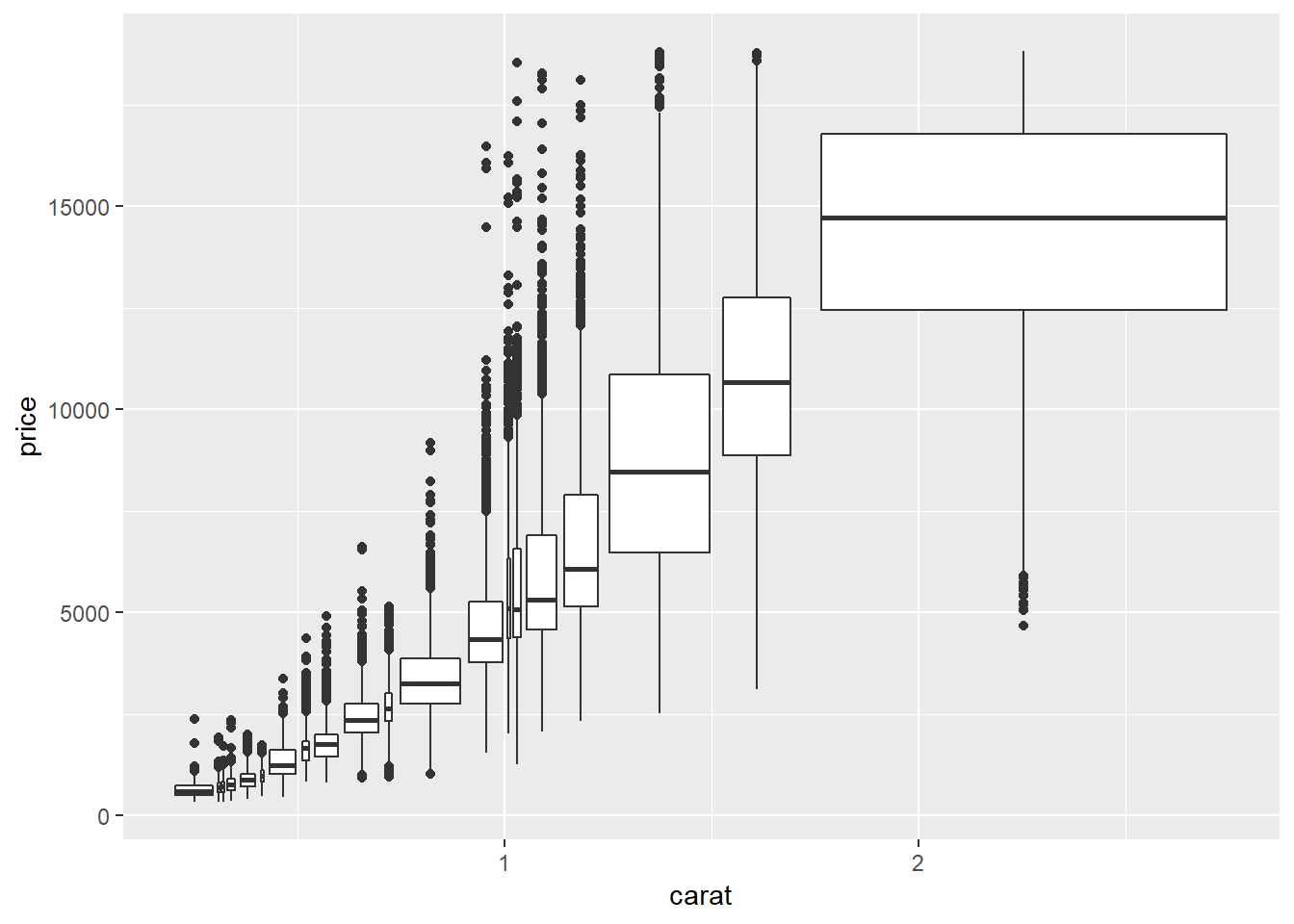
These methods don’t seem to work quite as well with violin plots or letter value plots:
##violin
ggplot(smaller, aes(x = carat, y = price))+
geom_violin(aes(group = cut_width(carat, 0.1)))
ggplot(smaller, aes(x = carat, y = price))+
geom_violin(aes(group = cut_number(carat, 20)))
##letter value
ggplot(smaller, aes(x = carat, y = price))+
lvplot::geom_lv(aes(group = cut_width(carat, 0.1)))
ggplot(smaller, aes(x = carat, y = price))+
lvplot::geom_lv(aes(group = cut_number(carat, 20)))
They look a little bit improved if you allow for fewer values per bin compared to the examples with geom_boxplot()
ggplot(smaller, aes(x = carat, y = price))+
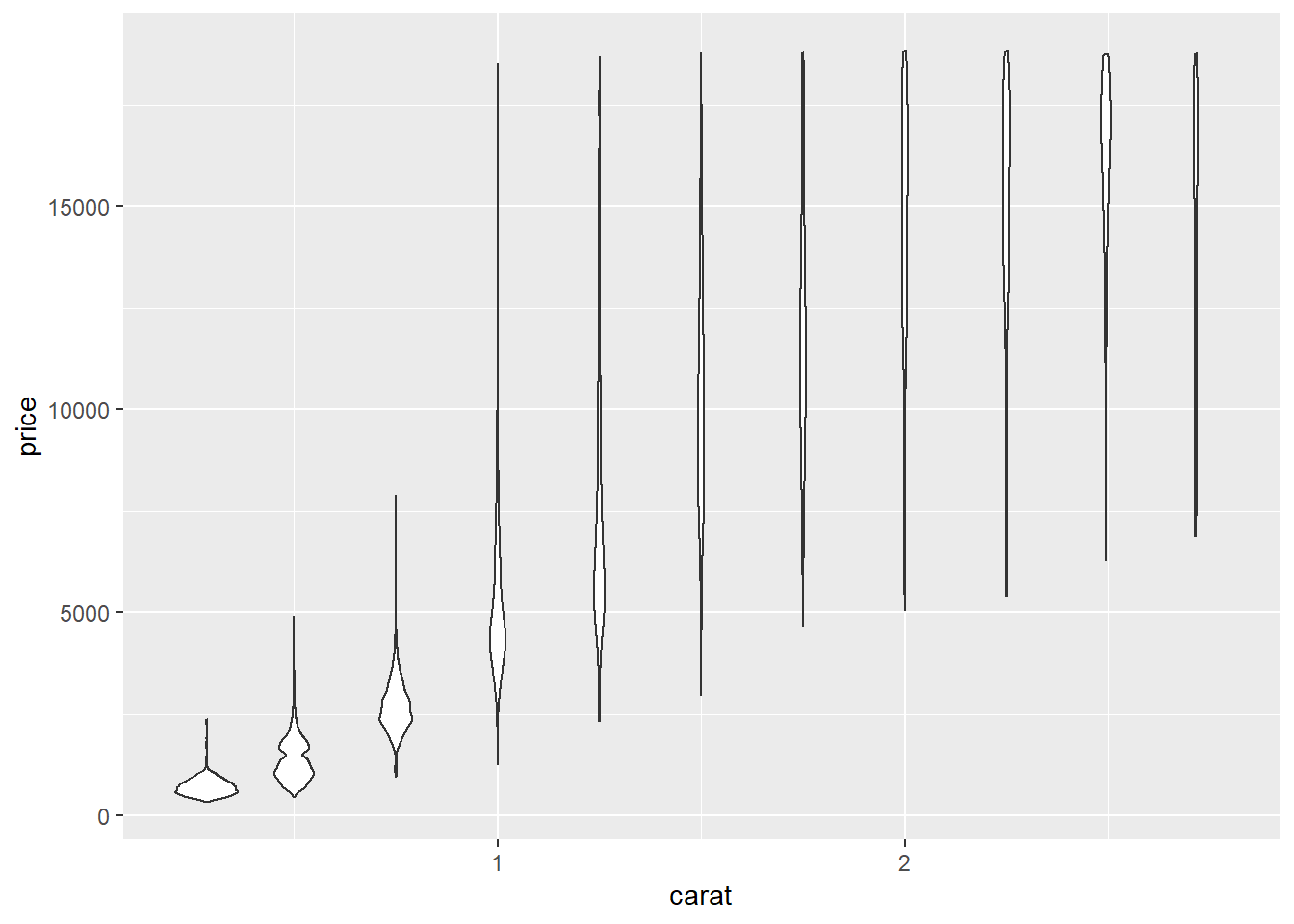
geom_violin(aes(group = cut_number(carat, 10)))
ggplot(smaller, aes(x = carat, y = price))+
geom_violin(aes(group = cut_width(carat, 0.25)))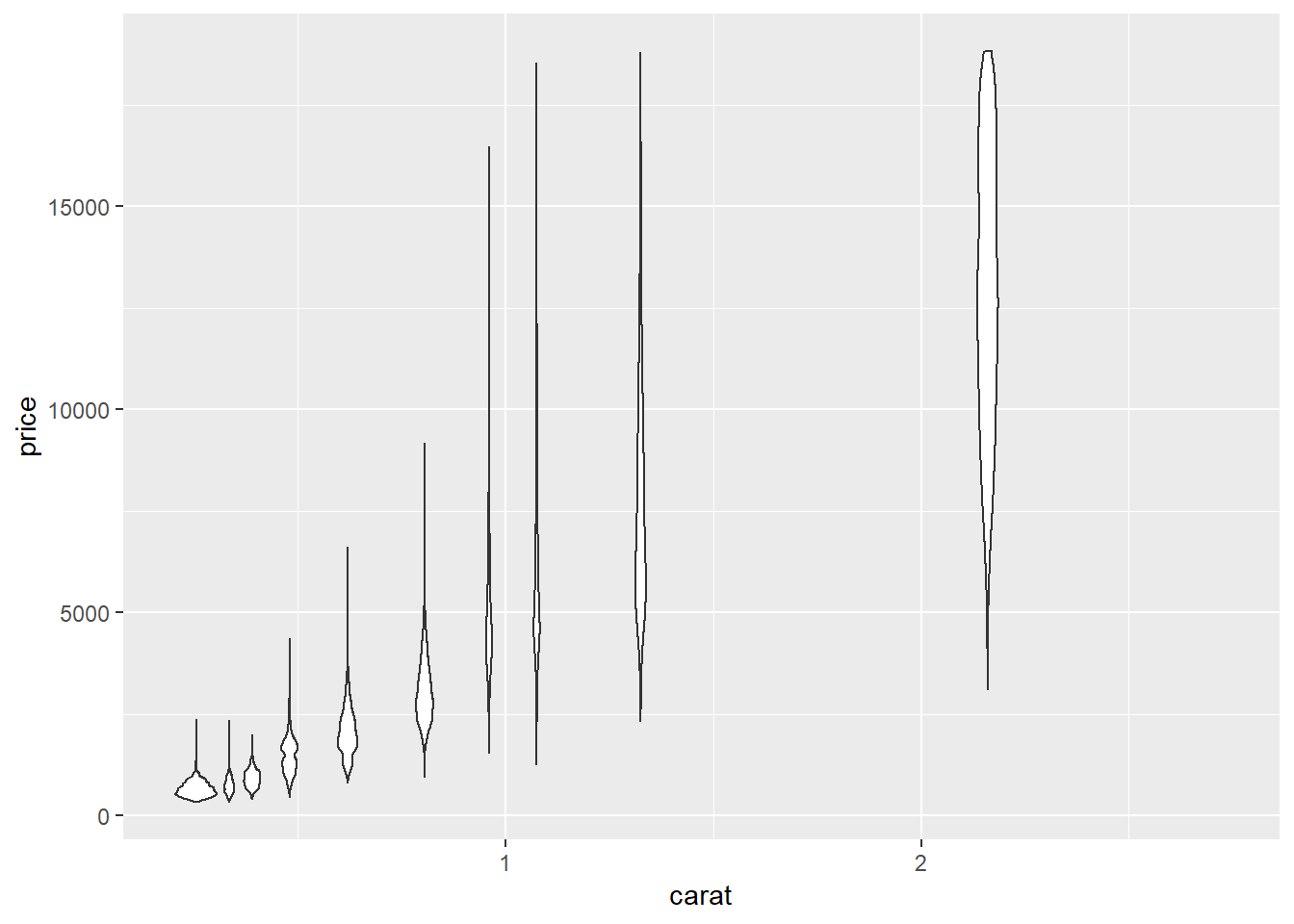
7.5.3.1.
1. Instead of summarising the conditional distribution with a boxplot, you could use a frequency polygon. What do you need to consider when using cut_width() vs cut_number()? How does that impact a visualisation of the 2d distribution of carat and price?
You should keep in mind how many lines you are going to create, they may overlap each other and look busy if you’re not careful.
ggplot(smaller, aes(x = price)) +
geom_freqpoly(aes(colour = cut_number(carat, 10)))## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.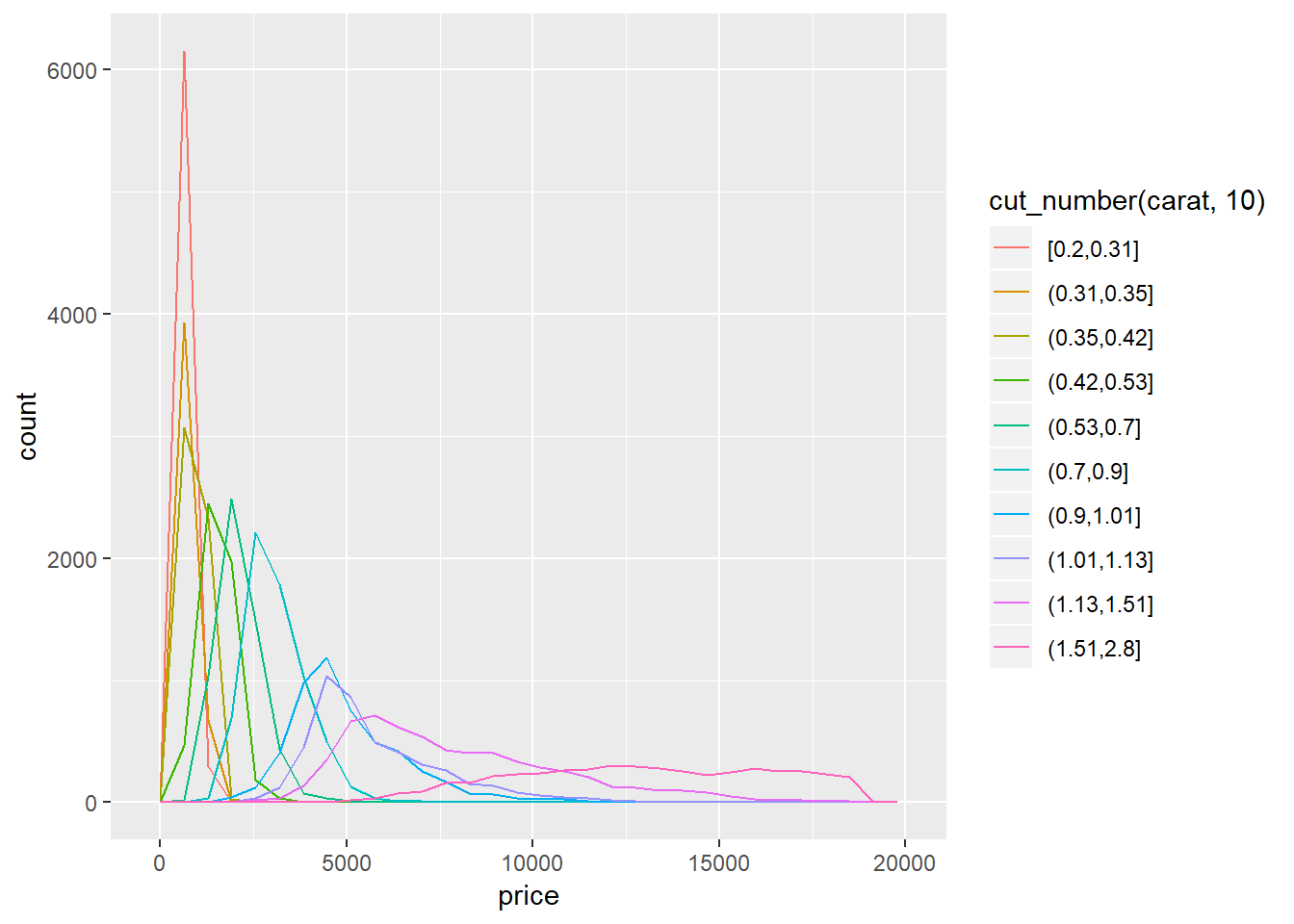
For the visualization below I wrapped it in the funciton plotly::ggplotly(). This funciton wraps your ggplot in html so that you can do things like hover over the points.
p <- ggplot(smaller, aes(x=price))+
geom_freqpoly(aes(colour = cut_width(carat, 0.25)))
plotly::ggplotly(p)## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.2. Visualise the distribution of carat, partitioned by price.
ggplot(diamonds, aes(x = price, y = carat))+
geom_violin(aes(group = cut_width(price, 2500)))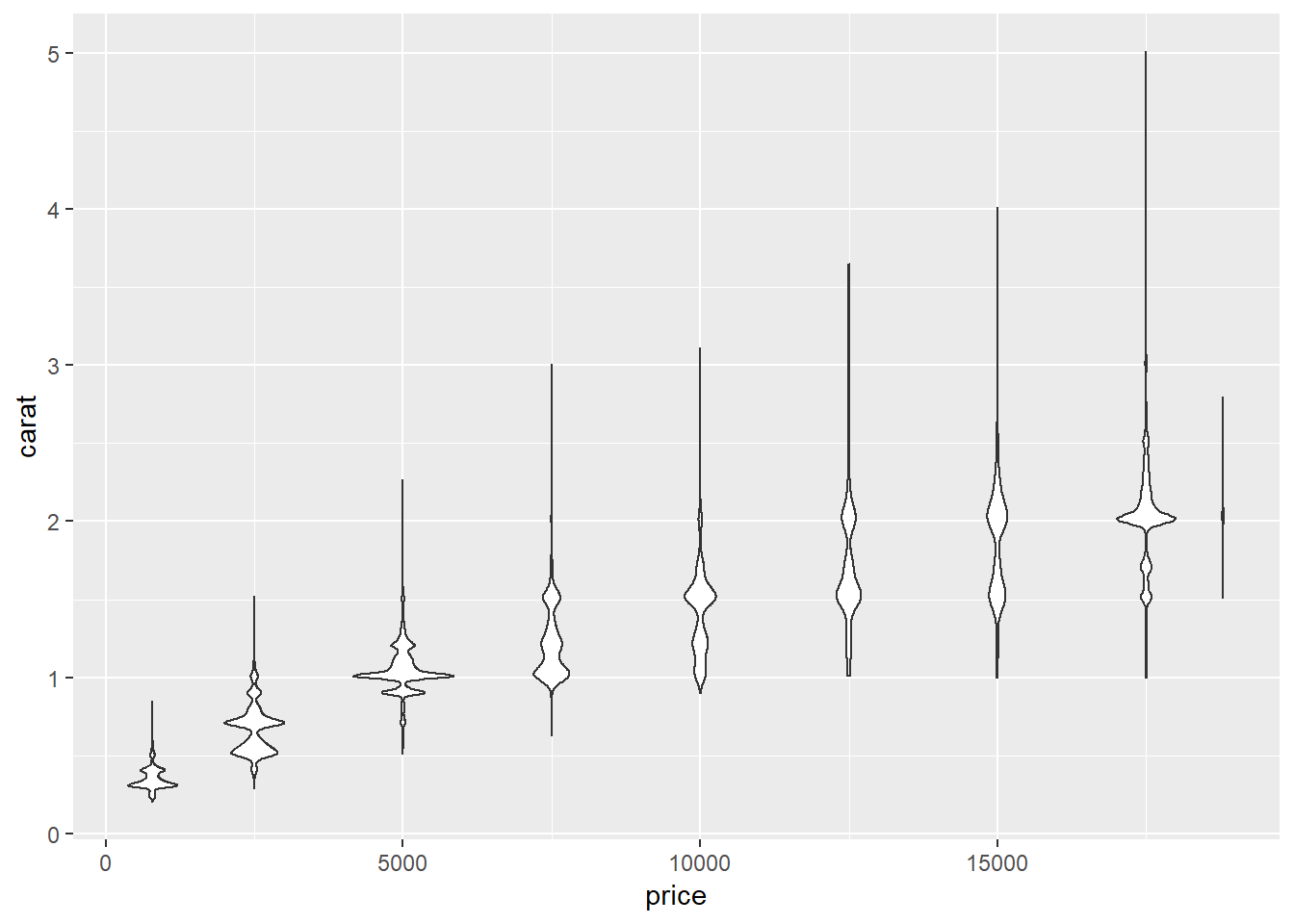
3. How does the price distribution of very large diamonds compare to small diamonds. Is it as you expect, or does it surprise you?
diamonds %>%
mutate(percent_rank = percent_rank(carat),
small = percent_rank < 0.025,
large = percent_rank > 0.975) %>%
filter(small | large) %>%
ggplot(aes(large, price)) +
geom_violin()+
facet_wrap(~large)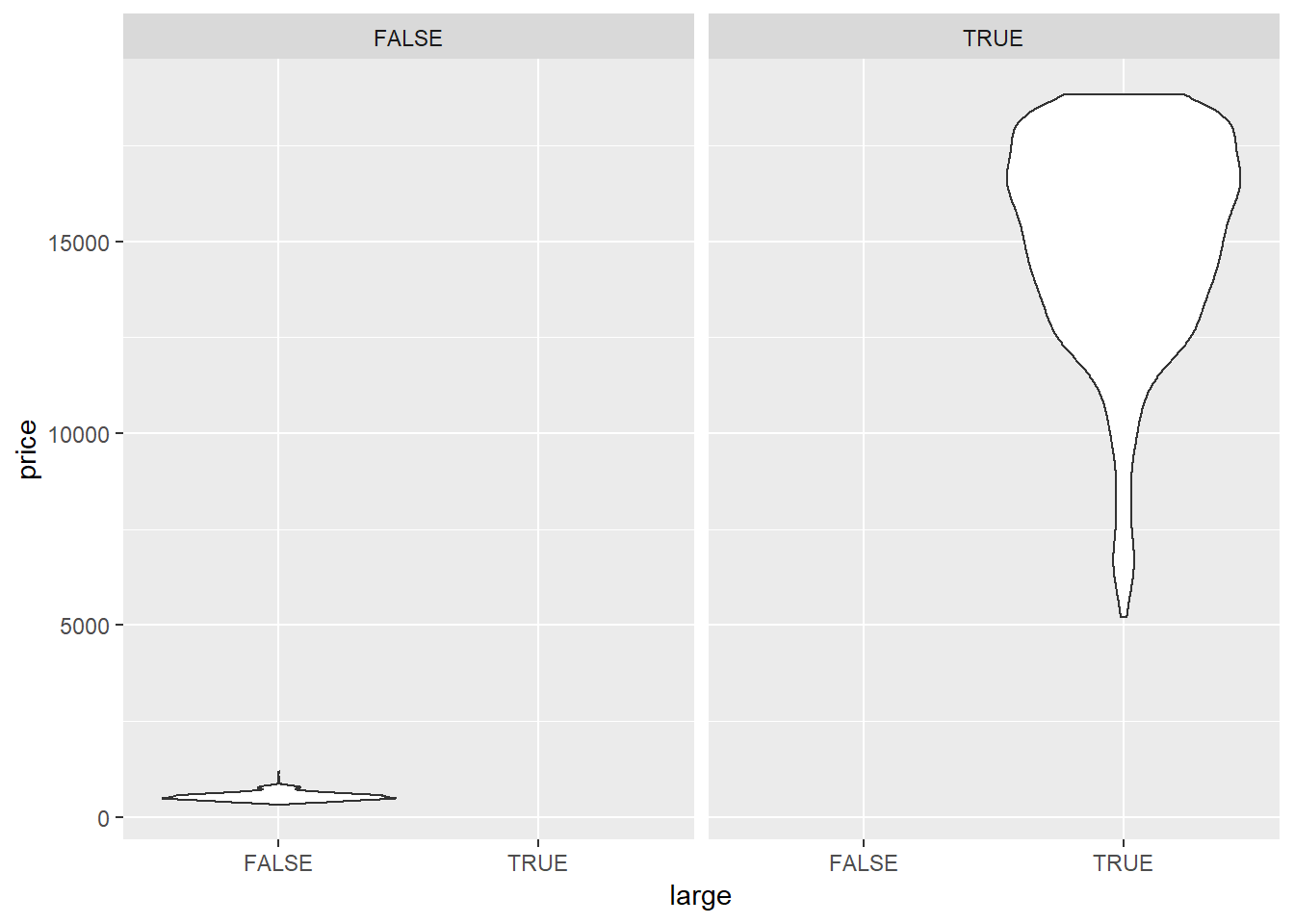
Small diamonds have a left-skewed price distribution, large diamonds have a right skewed price distribution.
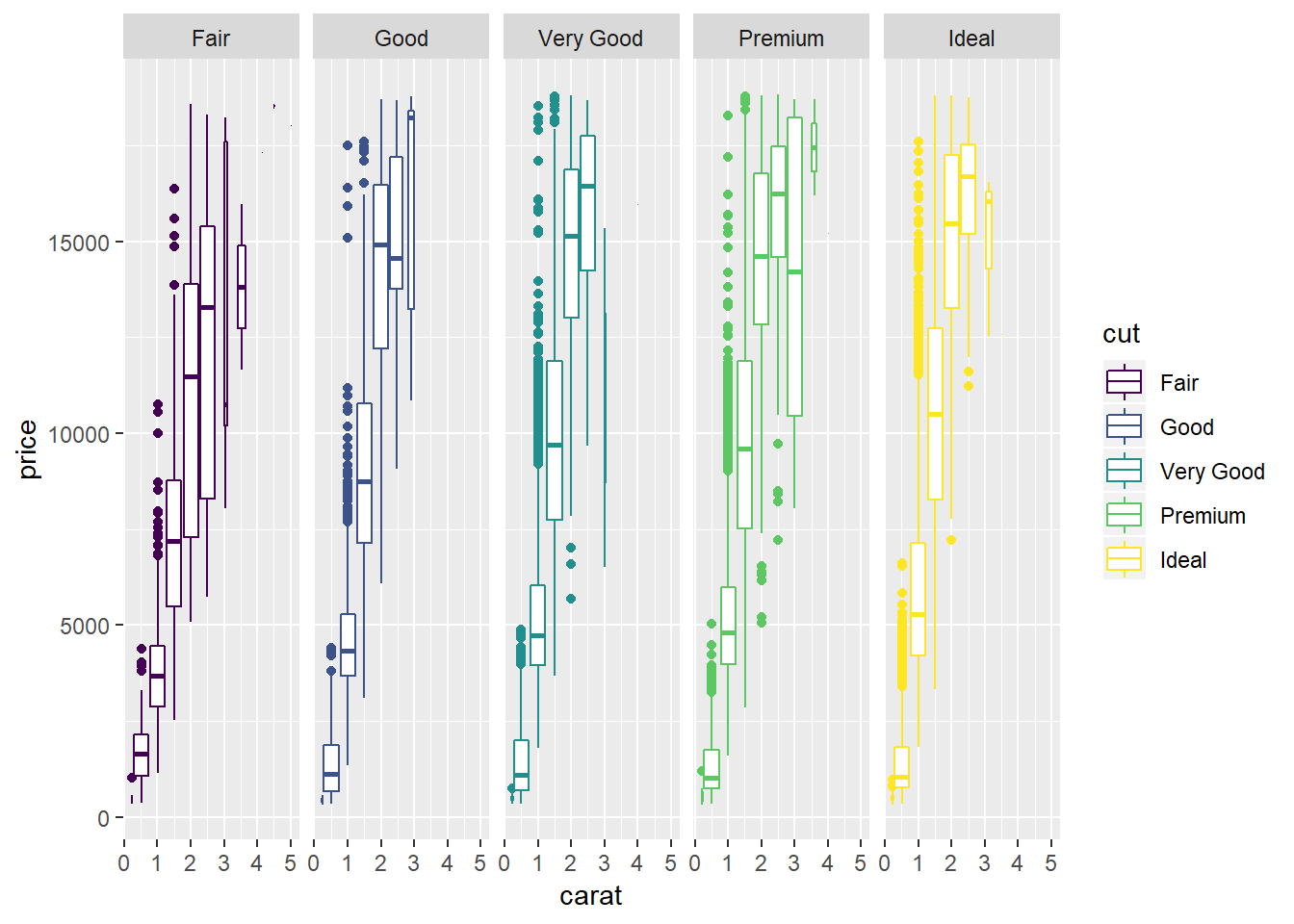
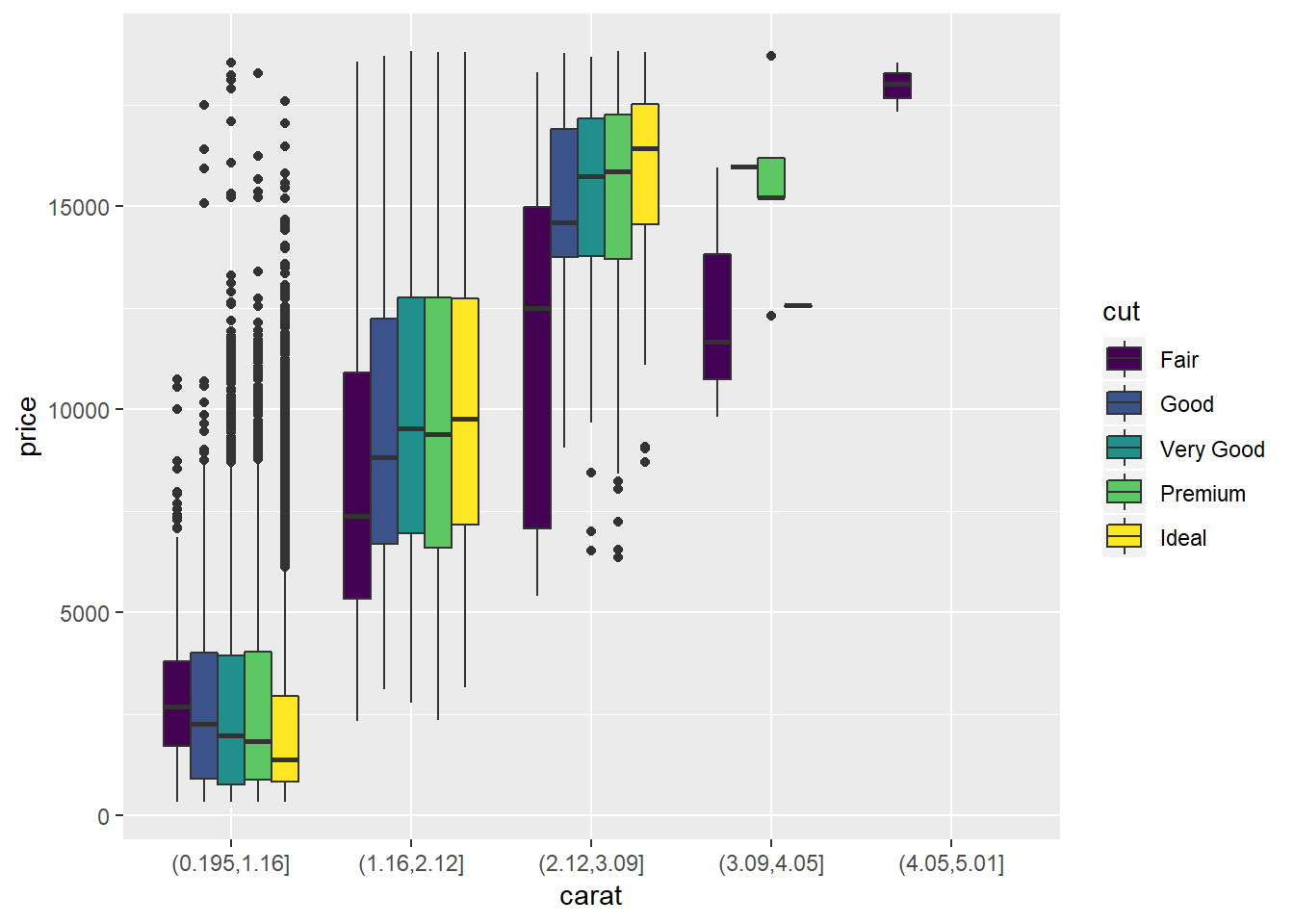
4. Combine two of the techniques you’ve learned to visualise the combined distribution of cut, carat, and price.
ggplot(diamonds, aes(x = carat, y = price))+
geom_jitter(aes(colour = cut), alpha = 0.2)+
geom_smooth(aes(colour = cut))## `geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'ggplot(diamonds, aes(x = carat, y = price))+
geom_boxplot(aes(group = cut_width(carat, 0.5), colour = cut))+
facet_grid(. ~ cut)
##I think this gives a better visualization, but is a little more complicated to produce, I also have the github version of ggplot and do not know whether the `preserve` arg is available in current CRAN installation.
diamonds %>%
mutate(carat = cut(carat, 5)) %>%
ggplot(aes(x = carat, y = price))+
geom_boxplot(aes(group = interaction(cut_width(carat, 0.5), cut), fill = cut), position = position_dodge(preserve = "single"))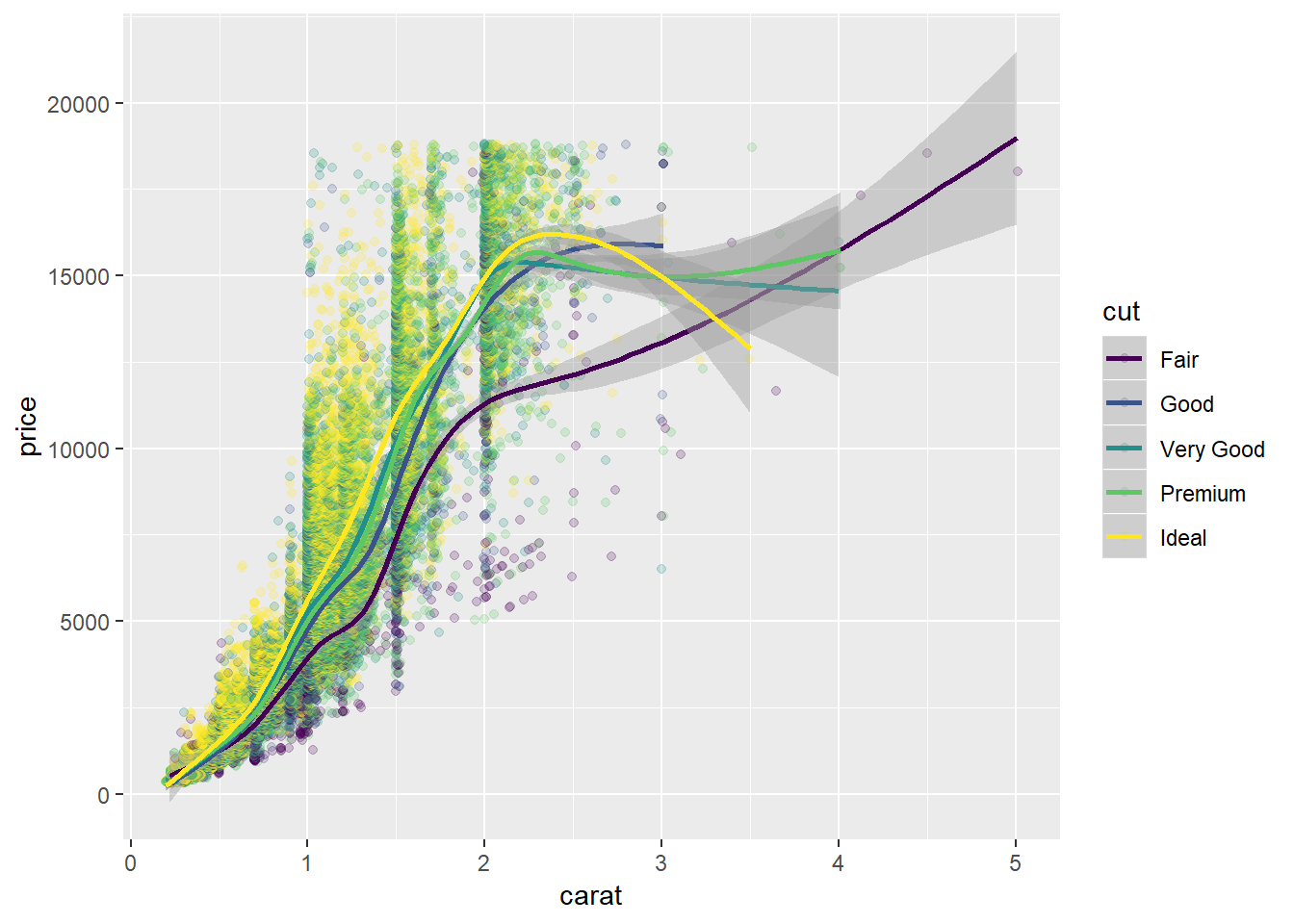
5.Two dimensional plots reveal outliers that are not visible in one dimensional plots. For example, some points in the plot below have an unusual combination of x and y values, which makes the points outliers even though their x and y values appear normal when examined separately.
ggplot(data = diamonds) +
geom_point(mapping = aes(x = x, y = y)) +
coord_cartesian(xlim = c(4, 11), ylim = c(4, 11))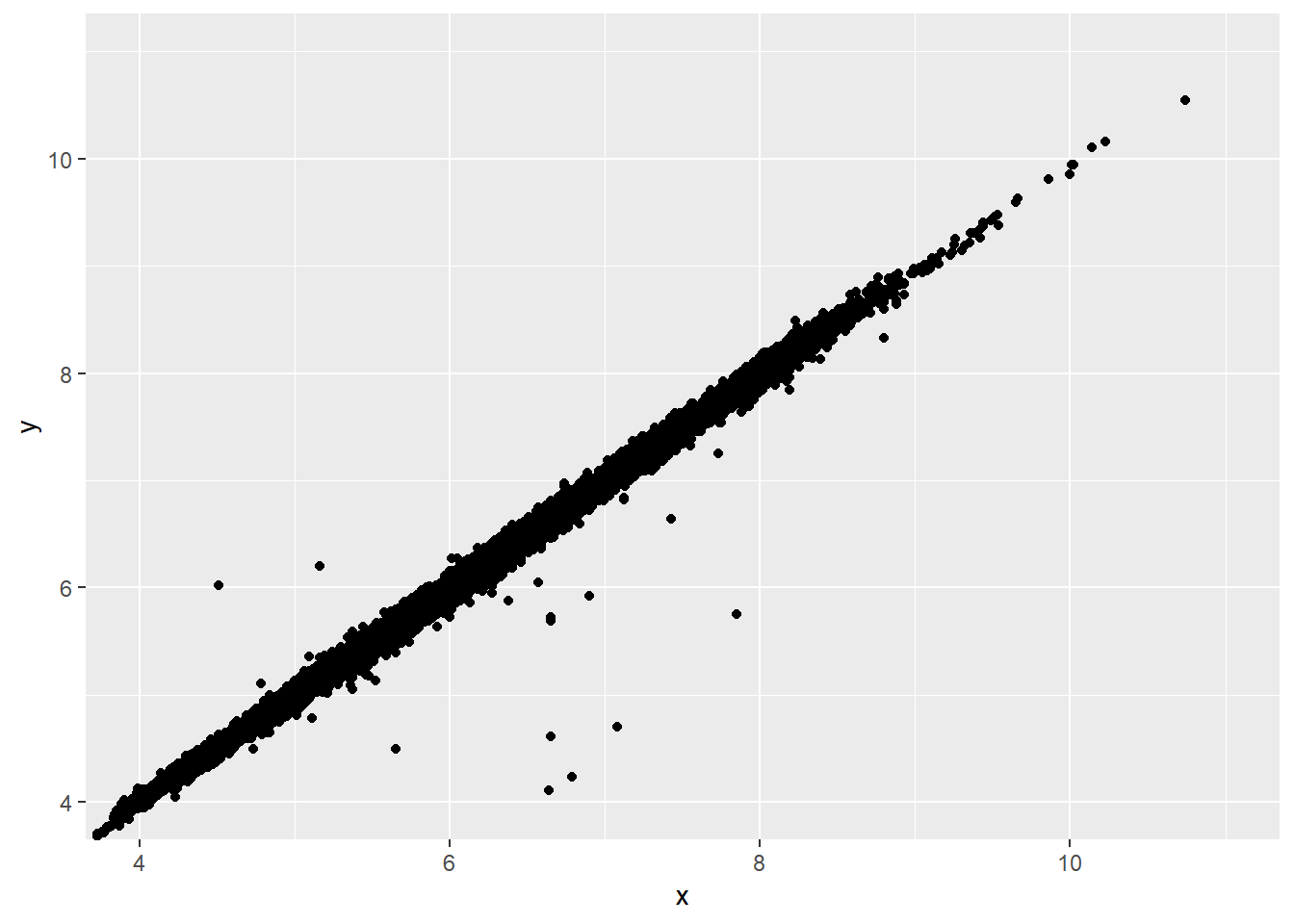
Why is a scatterplot a better display than a binned plot for this case?
Binned plots give less precise value estimates at each point (constrained by the granularity of the binning) so outliers do not show-up as clearly. They also show less precise relationships between the data. The level of variability (at least with boxplots) can also be tougher to intuit. For example, let’s look at the plot below as a binned boxplot.
ggplot(data = diamonds) +
geom_boxplot(mapping = aes(x = cut_width(x, 1), y = y)) +
coord_cartesian(xlim = c(4, 11), ylim = c(4, 11))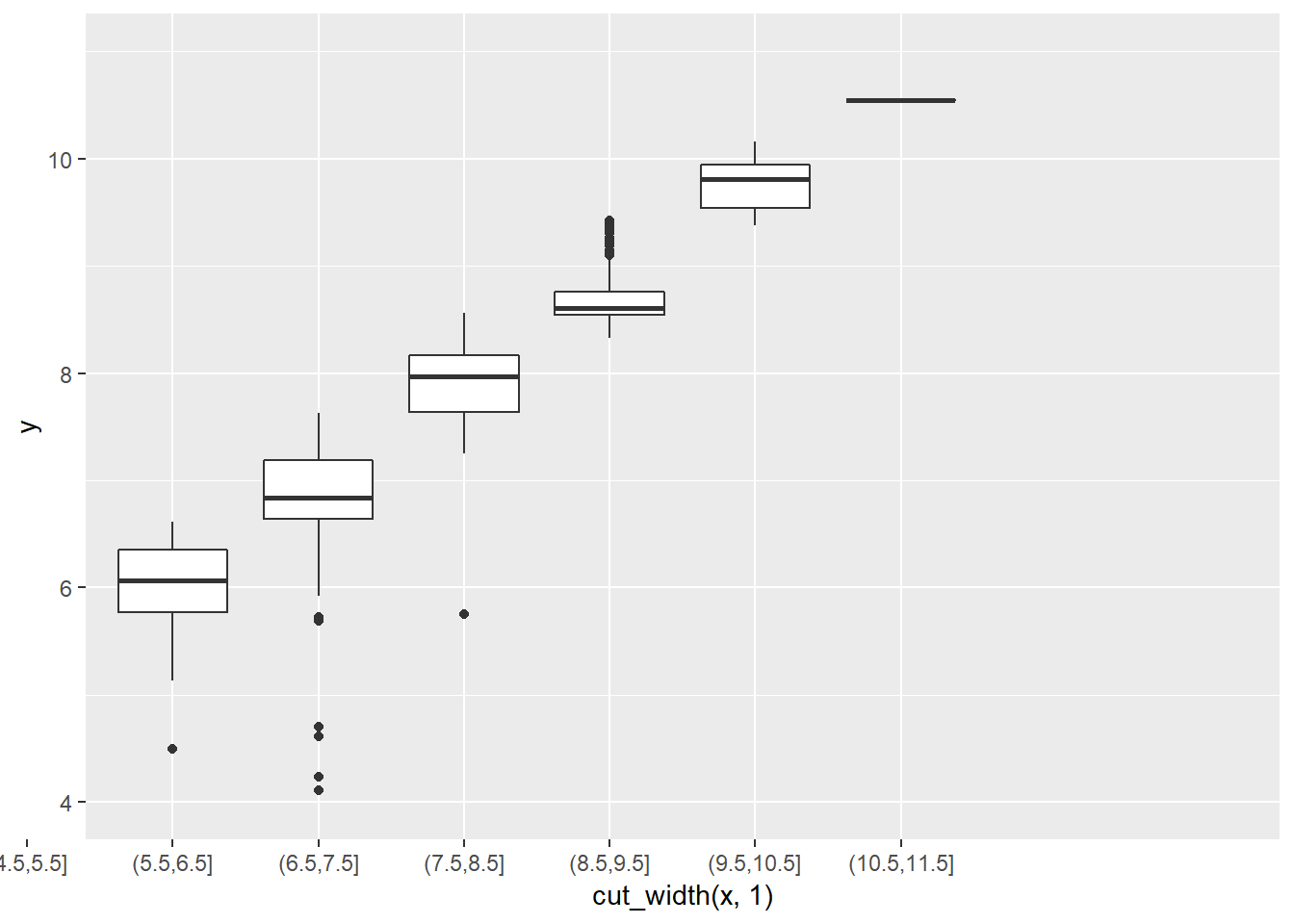
Appendix
7.5.2.1.2.
Plot below shows four regions I’ll split the country into. Seems like for a few destinations the lat and long points were likely misentered (probably backwards).
all_states <- map_data("state")
p <- geom_polygon(data = all_states,
aes(x = long, y = lat, group = group, label = NULL),
colour = "white", fill = "grey10")
dest_regions <- nycflights13::airports %>%
mutate(lat_cut = cut(percent_rank(lat), 2, labels = c("S", "N")),
lon_cut = cut(percent_rank(lon), 2, labels = c("W", "E")),
quadrant = paste0(lat_cut, lon_cut))
point_plot <- dest_regions %>%
ggplot(aes(lon, lat, colour = quadrant))+
p+
geom_point()
point_plot+
coord_quickmap()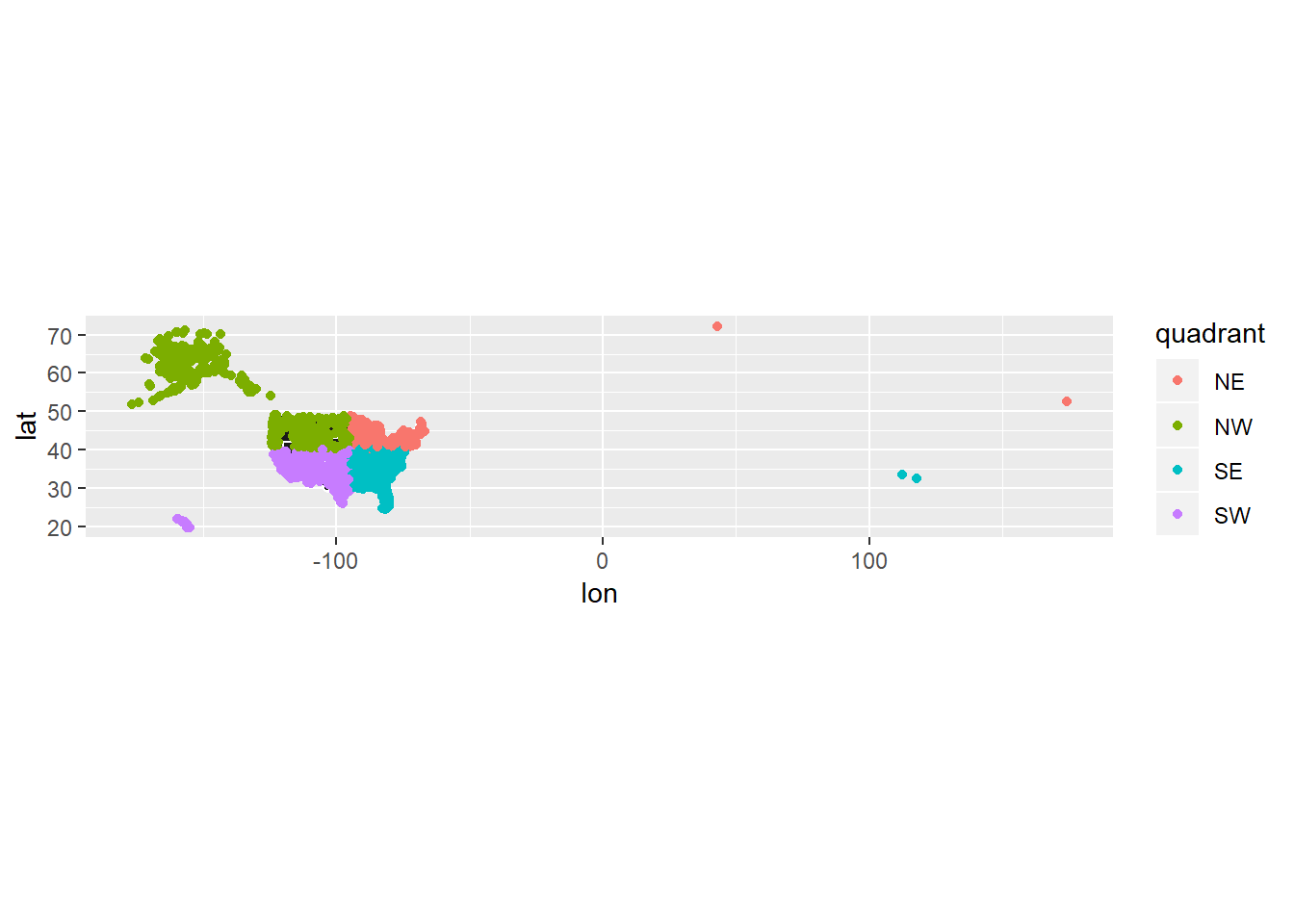
Now let’s join our region information with our flight data and do our calculations grouping by quadrant rather than dest. Note that those quadrants with NA (did not join with flights) looked to be Pueorto Rico or other non-state locations.
flights %>%
left_join(dest_regions, by = c("dest" = "faa")) %>%
group_by(quadrant, month) %>%
summarise(delay_mean = mean(dep_delay, na.rm=TRUE),
n = n()) %>%
mutate(sum_n = sum(n)) %>%
#the sum on n will be at the dest level here
# filter(sum_n > 10000) %>%
ggplot(aes(x = as.factor(month), y = quadrant, fill = delay_mean))+
geom_tile()+
scale_fill_gradient2(low = "blue", high = "red")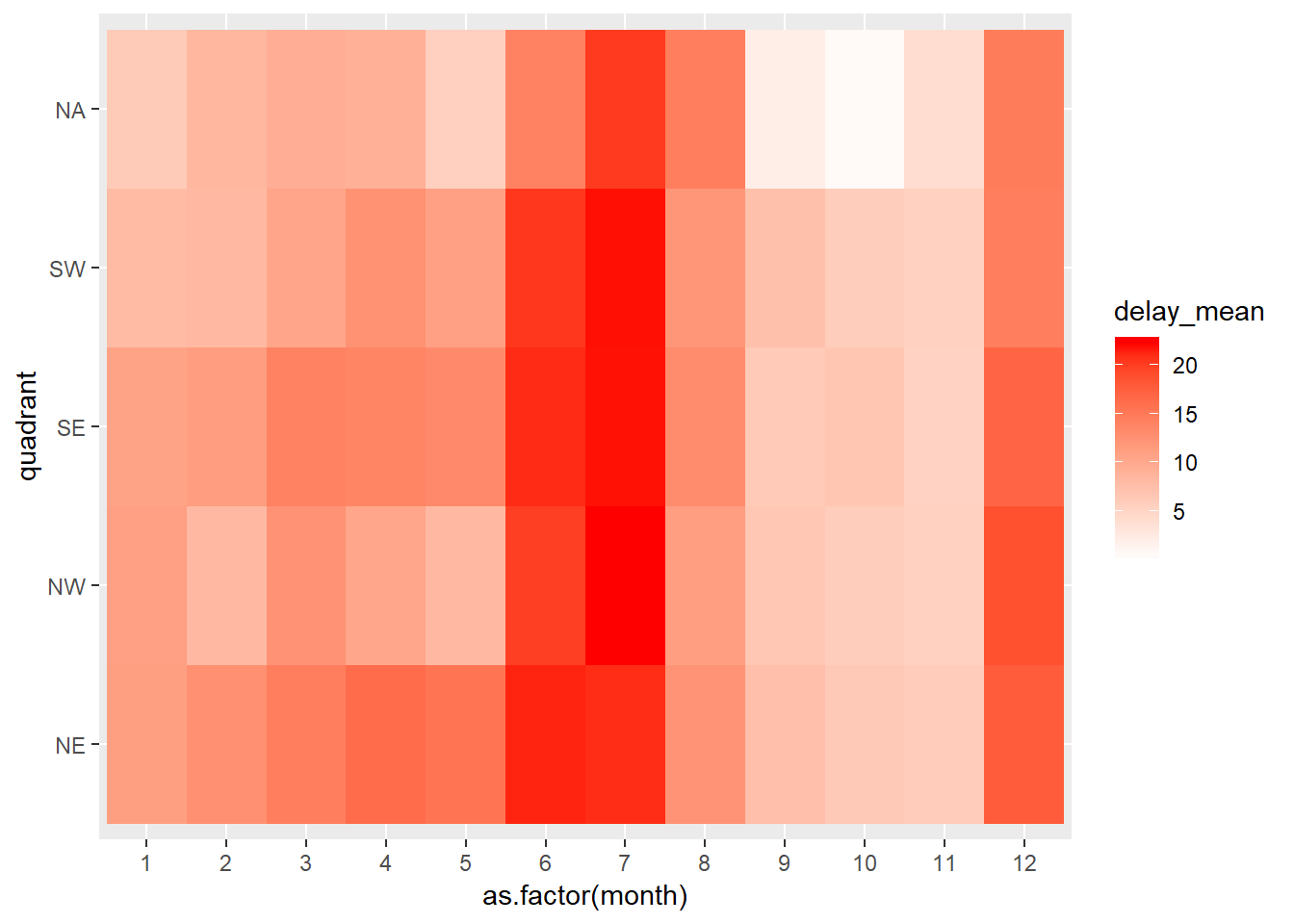
7.5.3.1.4.
To get the fill value to vary need to iterate through and make each graph seperate, can’t ust use facet.
diamonds_nest <- diamonds %>%
group_by(cut) %>%
tidyr::nest()
plot_free <- function(df, name){
ggplot(df)+
geom_bin2d(aes(carat, price))+
ggtitle(name)
}
gridExtra::grid.arrange(grobs = mutate(diamonds_nest, out = purrr::map2(data, cut, plot_free))$out)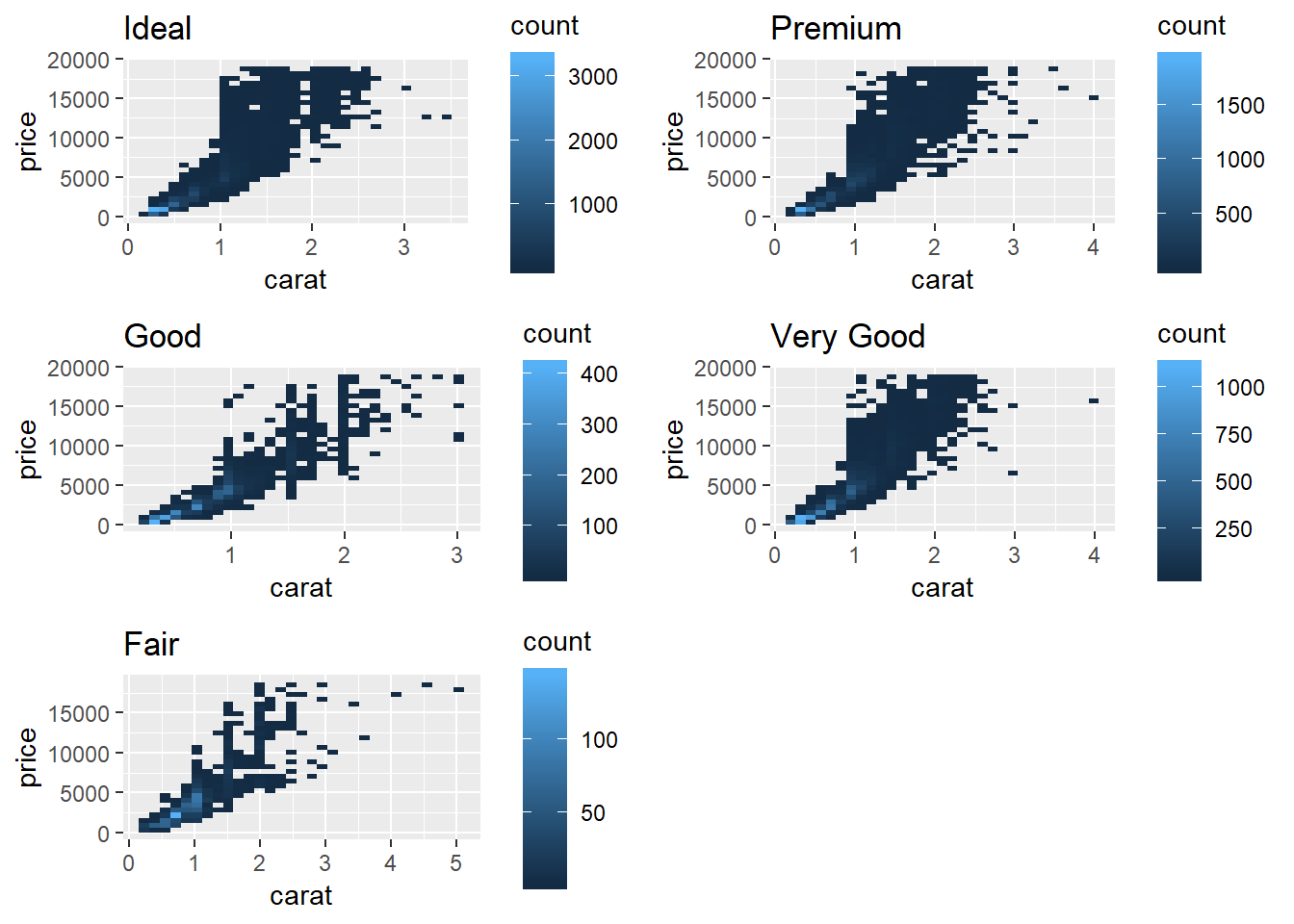
diamonds %>%
mutate(cut = forcats::as_factor(as.character(cut), levels = c("Fair", "Good", "Very Good", "Premium", "Ideal"))) %>%
# with(contrasts(cut))
lm(log(price) ~ log(carat) + cut, data = .) %>%
summary()##
## Call:
## lm(formula = log(price) ~ log(carat) + cut, data = .)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.52247 -0.16484 -0.00587 0.16087 1.38115
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 8.517337 0.001996 4267.70 <2e-16 ***
## log(carat) 1.695771 0.001910 887.68 <2e-16 ***
## cutPremium -0.078994 0.002810 -28.11 <2e-16 ***
## cutGood -0.153967 0.004046 -38.06 <2e-16 ***
## cutVery Good -0.076458 0.002904 -26.32 <2e-16 ***
## cutFair -0.317212 0.006632 -47.83 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.2545 on 53934 degrees of freedom
## Multiple R-squared: 0.9371, Adjusted R-squared: 0.9371
## F-statistic: 1.607e+05 on 5 and 53934 DF, p-value: < 2.2e-16contrasts(diamonds$cut)## .L .Q .C ^4
## [1,] -0.6324555 0.5345225 -3.162278e-01 0.1195229
## [2,] -0.3162278 -0.2672612 6.324555e-01 -0.4780914
## [3,] 0.0000000 -0.5345225 -4.095972e-16 0.7171372
## [4,] 0.3162278 -0.2672612 -6.324555e-01 -0.4780914
## [5,] 0.6324555 0.5345225 3.162278e-01 0.1195229count(diamonds, cut)## # A tibble: 5 x 2
## cut n
## <ord> <int>
## 1 Fair 1610
## 2 Good 4906
## 3 Very Good 12082
## 4 Premium 13791
## 5 Ideal 21551