Ch. 20: Vectors
Key questions:
- 20.3.5, #1
- 20.4.6. #1, 4, 5
Types of vectors, not including augmented types:
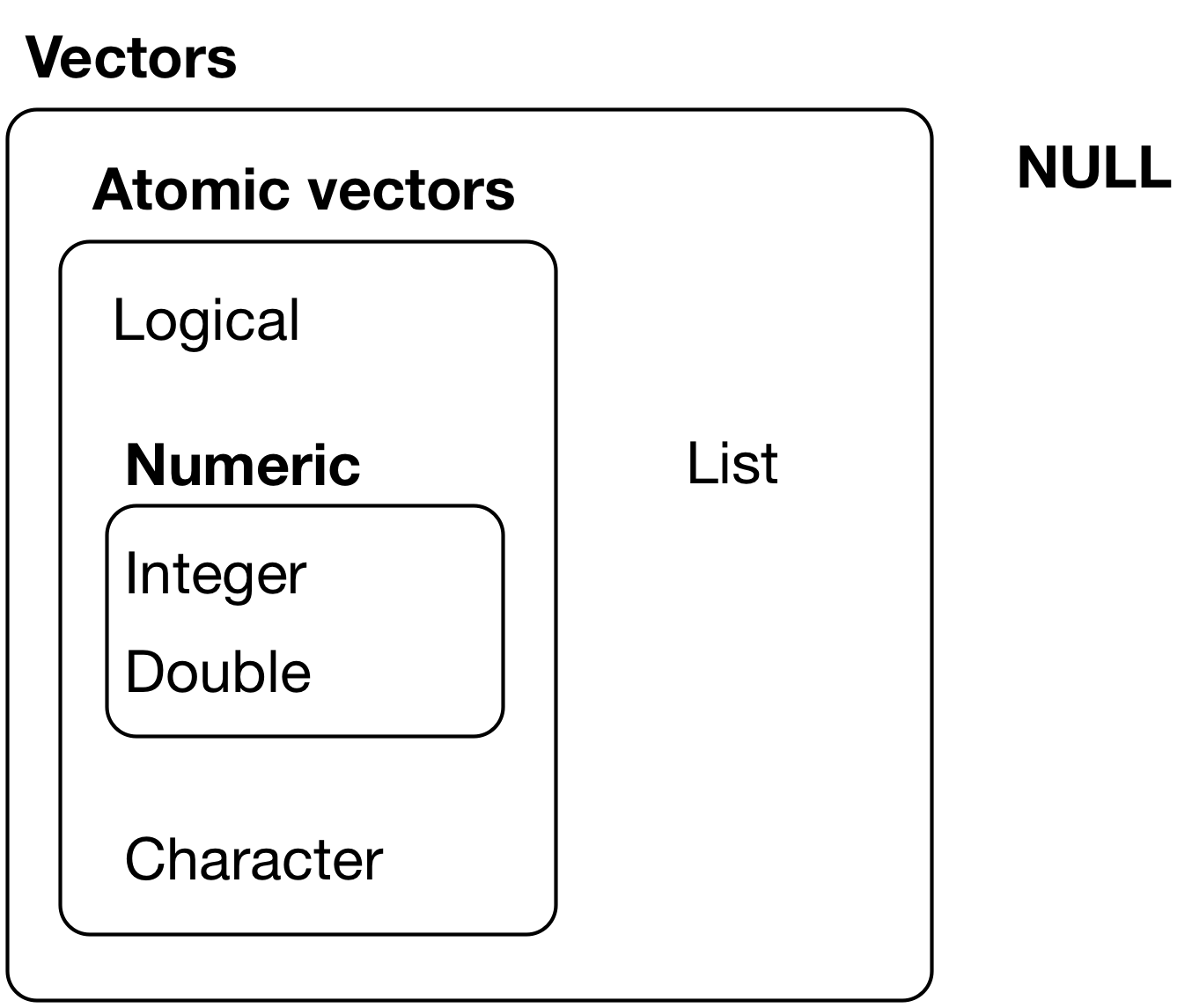
- Check special value types:
is.finite,is.infinite,is.na,is.nan

typeofretruns type of vectorlengthreturns length of vectorpryr::object_sizeview size of object stored- specific
NAvalues can be defined explicitly withNA_integer_,NA_real_,NA_character_(usually don’t need to know) - explicitly differentiate integers from doubles with
10Lv10 - explicit coersion functions:
as.logical,as.integer,as.double,as.character, or usecol_[types]when reading in so that coersion done at source - test functions from
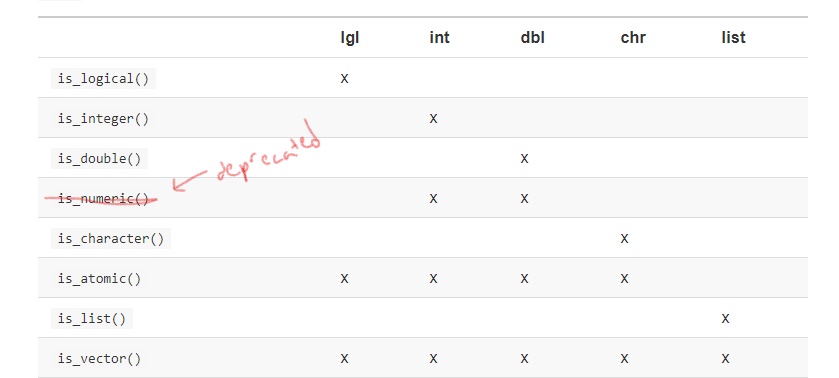
purrrpackage that are more consistent than base R’s
Purrr versions for testing types:
set_nameslets you set names after the fact, e.g.set_names(1:3, c("a", "b", "c"))- For more details on subsetting: http://adv-r.had.co.nz/Subsetting.html#applications
strchecks structure (excellent for use with lists)attrandattributesget and set attributes- main types of attributes: Names, Dimensions/dims, Class. Class is important for object oriented programming which is covered in more detail here: http://adv-r.had.co.nz/OO-essentials.html#s3
- Used together to investigate details of code for functions
useMethodin function syntax indicates it is a generic functionmethodslists all methods within a genericgetS3methodto show specific implementation of a method
as.Date## function (x, ...)
## UseMethod("as.Date")
## <bytecode: 0x000000001d6f1aa0>
## <environment: namespace:base>methods("as.Date")## [1] as.Date.character as.Date.default as.Date.factor as.Date.numeric
## [5] as.Date.POSIXct as.Date.POSIXlt
## see '?methods' for accessing help and source codegetS3method("as.Date", "default")## function (x, ...)
## {
## if (inherits(x, "Date"))
## x
## else if (is.logical(x) && all(is.na(x)))
## .Date(as.numeric(x))
## else stop(gettextf("do not know how to convert '%s' to class %s",
## deparse(substitute(x)), dQuote("Date")), domain = NA)
## }
## <bytecode: 0x0000000019e1f0e8>
## <environment: namespace:base>- Some tidyverse functions are not always easy to unpack with just the above34
- Augmented vectors: vectors with additional attributes, e.g. factors (levels, class = factors), dates and datetimes (tzone, class = (POSIXct, POSIXt)), POSIXlt (names, class = (POSIXLt, POSIXt)), tibbles (names, class = (tbl_df, tbl, data.frame), row.names) – in the integer, double and double, list, list types.
- data frames only have class
data.frame, whereas tibbles havetbl_df, andtblas well
- data frames only have class
classget or set class attributeunclassreturns copy with ‘class’ attribute removed
20.3: Important types of atomic vector
20.3.5
Describe the difference between
is.finite(x)and!is.infinite(x).is.finiteandis.infinitereturnFALSEforNAorNaNvalues, therefore these values becomeTRUEwhen negated as in the latter case, e.g.:
is.finite(c(6,11,-Inf, NA, NaN))## [1] TRUE TRUE FALSE FALSE FALSE!is.infinite(c(6,11,-Inf, NA, NaN))## [1] TRUE TRUE FALSE TRUE TRUERead the source code for
dplyr::near()(Hint: to see the source code, drop the()). How does it work?- safer way to test equality of floating point numbers (as has some tolerance for differences caused by rounding)
- it checks if the difference between the value is within
tolwhich by default is.Machine$double.eps^0.5
A logical vector can take 3 possible values. How many possible values can an integer vector take? How many possible values can a double take? Use google to do some research.
- Part of the point here is that it’s not ‘infinite’ like someone may be tempted to answer – it’s constrained by memory of the machine
- For integer it is 2 * 2 * 10^9
- For double it is 2 * 2 * 10^308
Brainstorm at least four functions that allow you to convert a double to an integer. How do they differ? Be precise.
as.integer,as.factor(technically is going to a factor – but this class is built on top of integers),round,floor,ceiling, these last 3 though do not change the type, which would remain a type double
What functions from the
readrpackage allow you to turn a string into logical, integer, and double vector?- The appropriate
parse_*orcol_*functions
- The appropriate
20.4: Using atomic vectors
20.4.6
What does
mean(is.na(x))tell you about a vectorx? What aboutsum(!is.finite(x))?- percentage that are
NAorNaN - number that are either
Inf,-Inf,NAorNaN
- percentage that are
Carefully read the documentation of
is.vector(). What does it actually test for? Why doesis.atomic()not agree with the definition of atomic vectors above?is.vectortests if it is a specific type of vector with no attributes other than names. This second requirement means that any augmented vectors such as factors, dates, tibbles all would return false.is.atomicreturns TRUE tois.atomic(NULL)despite this representing the empty set.
Compare and contrast
setNames()withpurrr::set_names().- both assign names after fact
purrr::set_namesis stricter and returns an error in situations like the following where assetNamesdoes not:
setNames(1:4, c("a"))## a <NA> <NA> <NA> ## 1 2 3 4set_names(1:4, c("a"))## Error: `nm` must be `NULL` or a character vector the same length as `x`Create functions that take a vector as input and returns:
x <- c(-3:14, NA, Inf, NaN)- The last value. Should you use
[or[[?
return_last <- function(x) x[[length(x)]] return_last(x)## [1] NaN- The elements at even numbered positions.
return_even <- function(x) x[((1:length(x)) %% 2 == 0)] return_even(x)## [1] -2 0 2 4 6 8 10 12 14 Inf- Every element except the last value.
return_not_last <- function(x) x[-length(x)] return_not_last(x)## [1] -3 -2 -1 0 1 2 3 4 5 6 7 8 9 10 11 12 13 ## [18] 14 NA Inf- Only even numbers (and no missing values).
#only even and not na return_even_no_na <- function(x) x[((1:length(x)) %% 2 == 0) & !is.na(x)] return_even_no_na(x)## [1] -2 0 2 4 6 8 10 12 14 Inf- The last value. Should you use
Why is
x[-which(x > 0)]not the same asx[x <= 0]?x[-which(x > 0)] #which only reports the indices of the matches, so specifies all to be removed## [1] -3 -2 -1 0 NA NaNx[x <= 0] #This method reports T/F'sNaN is converted into NA## [1] -3 -2 -1 0 NA NA- in the 2nd instance,
NaNs will get converted toNA
- in the 2nd instance,
What happens when you subset with a positive integer that’s bigger than the length of the vector? What happens when you subset with a name that doesn’t exist?
- In both cases you get back an
NA(though it seems to take longer in the case when subsetting by a name that doesn’t exist).
- In both cases you get back an
20.5: Recursive vectors (lists)
Example of subsetting items from a list:
a <- list(a = 1:3, b = "a string", c = pi, d = list(c(-1,-2), -5))
a[[4]][[1]]## [1] -1 -2# equivalent alternatives:
# a$d[[1]]
# a[4][[1]][[1]]- 3 ways of subsetting
[],[[]],$
20.5.4.
a <- list(a = 1:3, b = "a string", c = pi, d = list(-1, -5))Draw the following lists as nested sets:
list(a, b, list(c, d), list(e, f))list(list(list(list(list(list(a))))))
- I did not conform with Hadley’s square v rounded syntax, but hopefully this gives a sense of what the above are:
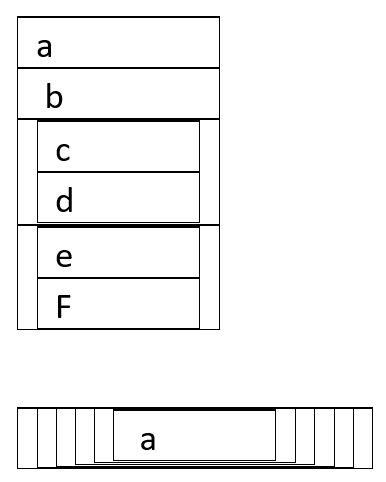
drawings 1 and 2 for 20.5.4.
What happens if you subset a tibble as if you’re subsetting a list? What are the key differences between a list and a tibble?
- Dataframe is just a list of vectors (columns) – with the restriction that each column has the same number of elements whereas lists do not have this requirement
- Dataframe structure better connects elements by row structure, making subsetting by the qualities of these values much easier
20.7: Augmented vectors
20.7.4
What does
hms::hms(3600)return?x <- hms::hms(3600)How does it print?
print(x)## 01:00:00What primitive type is the augmented vector built on top of?
typeof(x)## [1] "double"What attributes does it use?
attributes(x)## $class ## [1] "hms" "difftime" ## ## $units ## [1] "secs"Try and make a tibble that has columns with different lengths. What happens?
- if the column is length one it will repeat for the length of the other column(s), otherwise if it is not the same length it will return an error
tibble(x = 1:4, y = 5:6) #error## Error: Tibble columns must have consistent lengths, only values of length one are recycled: ## * Length 2: Column `y` ## * Length 4: Column `x`tibble(x = 1:5, y = 6) #can have length 1 that repeats## # A tibble: 5 x 2 ## x y ## <int> <dbl> ## 1 1 6 ## 2 2 6 ## 3 3 6 ## 4 4 6 ## 5 5 6Based on the definition above, is it ok to have a list as a column of a tibble?
- Yes, as long as the number of elements align with the other length of the other columns – this will come-up a lot in the modeling chapters.
Appendix
Subsetting nested lists
x <- list("a", list(list("c", "d"), "e2"), list("e", "f"))
x## [[1]]
## [1] "a"
##
## [[2]]
## [[2]][[1]]
## [[2]][[1]][[1]]
## [1] "c"
##
## [[2]][[1]][[2]]
## [1] "d"
##
##
## [[2]][[2]]
## [1] "e2"
##
##
## [[3]]
## [[3]][[1]]
## [1] "e"
##
## [[3]][[2]]
## [1] "f"It can be confusing how to subset items in a nested list, lists output helps tell you the subsetting needed to extract particular items. For example, to output list("c", "d") requires x[[2]][[1]], to output just d requires x[[2]][[1]][[2]]
Subset nested lists:

For example try typing in
?select,methods("select"),getS3method("select", "data.frame"), ordplyr:::select_implinto the console and the output may not immediately illuminate for you howselect()works. If interested in more advanced topics, see Advanced R Progamming.↩